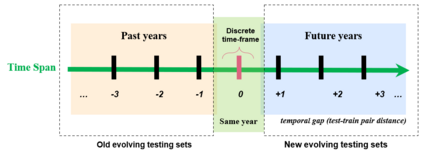
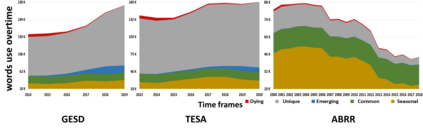
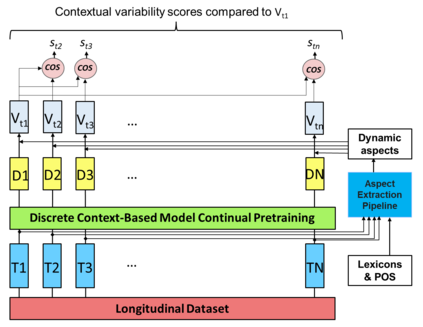
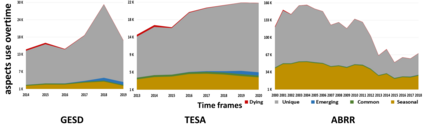
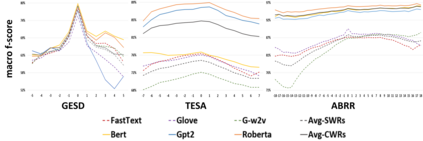
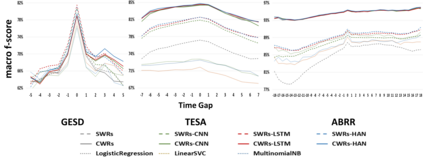
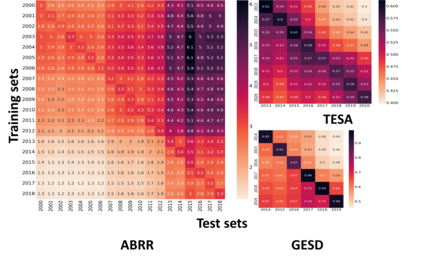
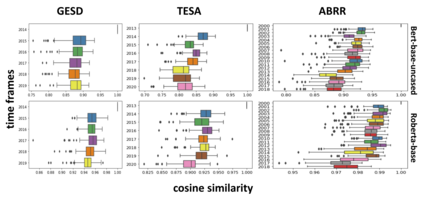
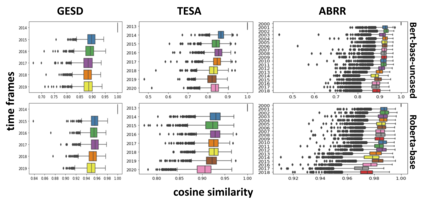
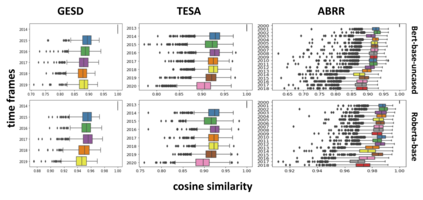
Performance of text classification models can drop over time when new data to be classified is more distant in time from the data used for training, due to naturally occurring changes in the data, such as vocabulary change. A solution to this is to continually label new data to retrain the model, which is, however, often unaffordable to be performed regularly due to its associated cost. This raises important research questions on the design of text classification models that are intended to persist over time: do all embedding models and classification algorithms exhibit similar performance drops over time and is the performance drop more prominent in some tasks or datasets than others? With the aim of answering these research questions, we perform longitudinal classification experiments on three datasets spanning between 6 and 19 years. Findings from these experiments inform the design of text classification models with the aim of preserving performance over time, discussing the extent to which one can rely on classification models trained from temporally distant training data, as well as how the characteristics of the dataset impact this.
翻译:当需要分类的新数据在时间上比培训所用的数据更加遥远时,文本分类模型的性能会随时间而下降,这是因为数据自然发生的变化,例如词汇的变化。一个解决办法是不断为新数据贴上标签,对模型进行再培训,然而,由于相关成本,通常无法定期进行这种培训。这就对打算长期维持的文本分类模型的设计提出了重要的研究问题:所有嵌入模型和分类算法的性能随时间推移而下降,而且在某些任务或数据集中的性能下降是否比其他任务或数据集更为显著?为了回答这些研究问题,我们对三个跨越6至19年的数据集进行了纵向分类试验。这些试验的结果为文本分类模型的设计提供了参考,目的是保持长期的性能,讨论人们在多大程度上可以依赖从时间遥远的培训数据中培训的分类模型,以及数据集的特征如何影响这种作用。