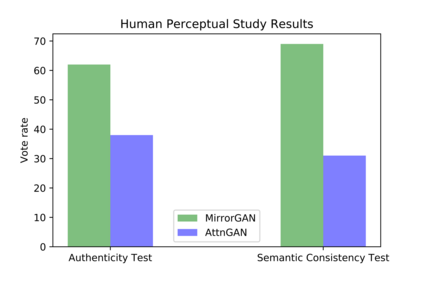
Generating an image from a given text description has two goals: visual realism and semantic consistency. Although significant progress has been made in generating high-quality and visually realistic images using generative adversarial networks, guaranteeing semantic consistency between the text description and visual content remains very challenging. In this paper, we address this problem by proposing a novel global-local attentive and semantic-preserving text-to-image-to-text framework called MirrorGAN. MirrorGAN exploits the idea of learning text-to-image generation by redescription and consists of three modules: a semantic text embedding module (STEM), a global-local collaborative attentive module for cascaded image generation (GLAM), and a semantic text regeneration and alignment module (STREAM). STEM generates word- and sentence-level embeddings. GLAM has a cascaded architecture for generating target images from coarse to fine scales, leveraging both local word attention and global sentence attention to progressively enhance the diversity and semantic consistency of the generated images. STREAM seeks to regenerate the text description from the generated image, which semantically aligns with the given text description. Thorough experiments on two public benchmark datasets demonstrate the superiority of MirrorGAN over other representative state-of-the-art methods.
翻译:从给定文本描述中生成图像有两个目标:视觉现实主义和语义一致性。虽然在利用基因对抗网络生成高质量和视觉现实图像方面取得了显著进展,但保证文本描述和视觉内容之间的语义一致性仍然是非常艰巨的。在本文件中,我们通过提出一个新的全球-本地注意和语义保留文本到图像到文字的框架,名为MiragGAN。MiraGAN利用了通过重写学习文本到图像生成的理念,由三个模块组成:语义嵌入模块(STEM)、级联图像生成全球-地方合作关注模块(GLAM)以及语义文本更新和对齐模块(STREAM)。STEM生成了文字和句级嵌入模块。GLAM有一个连锁结构,将目标图像从粗俗到微规模生成,利用本地文字关注和全球句注意逐步增强生成图像的多样性和语义一致性。STREAM试图将生成的文本描述从生成的图像中重新生成文本描述,用SARAN-SALM 模型展示了公共图像的高级性标定方法。