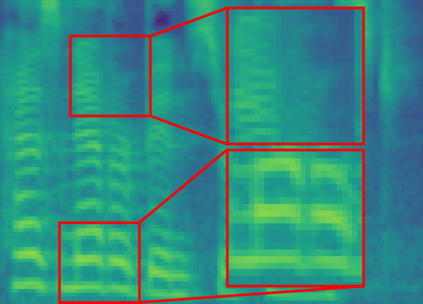
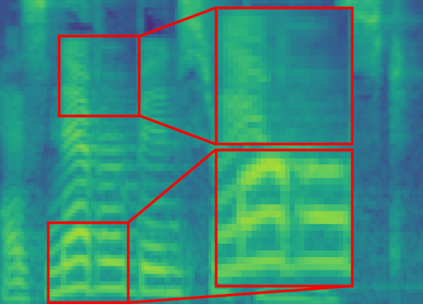
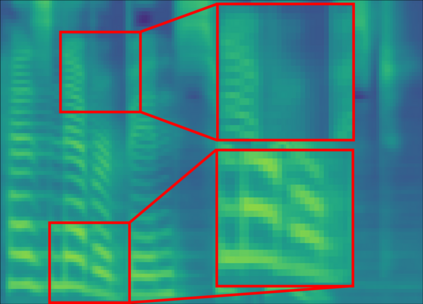
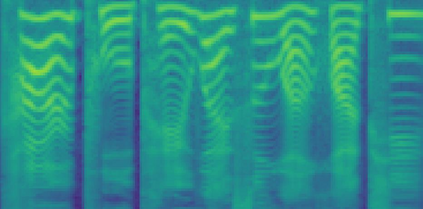
The recent progress in non-autoregressive text-to-speech (NAR-TTS) has made fast and high-quality speech synthesis possible. However, current NAR-TTS models usually use phoneme sequence as input and thus cannot understand the tree-structured syntactic information of the input sequence, which hurts the prosody modeling. To this end, we propose SyntaSpeech, a syntax-aware and light-weight NAR-TTS model, which integrates tree-structured syntactic information into the prosody modeling modules in PortaSpeech \cite{ren2021portaspeech}. Specifically, 1) We build a syntactic graph based on the dependency tree of the input sentence, then process the text encoding with a syntactic graph encoder to extract the syntactic information. 2) We incorporate the extracted syntactic encoding with PortaSpeech to improve the prosody prediction. 3) We introduce a multi-length discriminator to replace the flow-based post-net in PortaSpeech, which simplifies the training pipeline and improves the inference speed, while keeping the naturalness of the generated audio. Experiments on three datasets not only show that the tree-structured syntactic information grants SyntaSpeech the ability to synthesize better audio with expressive prosody, but also demonstrate the generalization ability of SyntaSpeech to adapt to multiple languages and multi-speaker text-to-speech. Ablation studies demonstrate the necessity of each component in SyntaSpeech. Source code and audio samples are available at https://syntaspeech.github.io
翻译:近期的非潜移式文本到语音(NAR-TTS) 模式的进展使得快速和高质量的语音合成成为可能。 然而,当前的 NAR-TTS 模式通常使用语音序列作为输入,因此无法理解输入序列的树结构合成信息,这伤害了编程的模拟。 为此,我们提议SyntaSpeech, 这是一种超小型的同步和轻量的 NAR-TTS 模式,它将树结构合成信息整合到PortaSpeech\cite{ren2021portaspech} 的模拟模块中。 具体地说,1 我们根据输入序列的依附树形结构构建了一个合成图形, 从而无法理解输入模型的树形结构。 我们建议SyntaSpeech(SyntaSpeech) 将提取的合成编码与PortaSpeechSpeech(波尔技术) 结合, 来改进编程预测。 3 我们引入多长导式分析器,以取代Portaute- Exlinet 后变现式的音频缩缩缩缩式数据, 也只能显示每个编程的精化版本的精化数据显示速度。