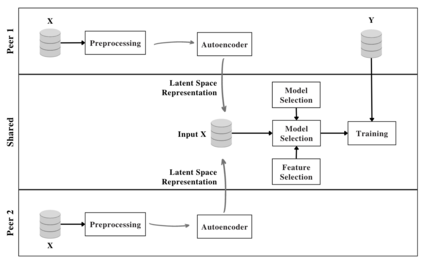
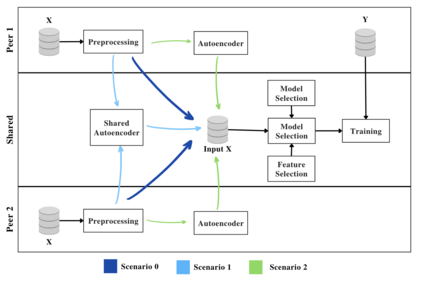
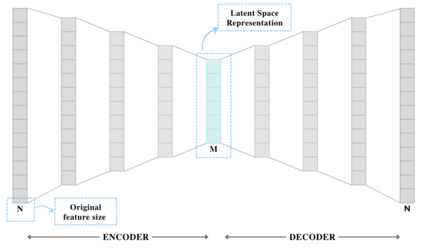
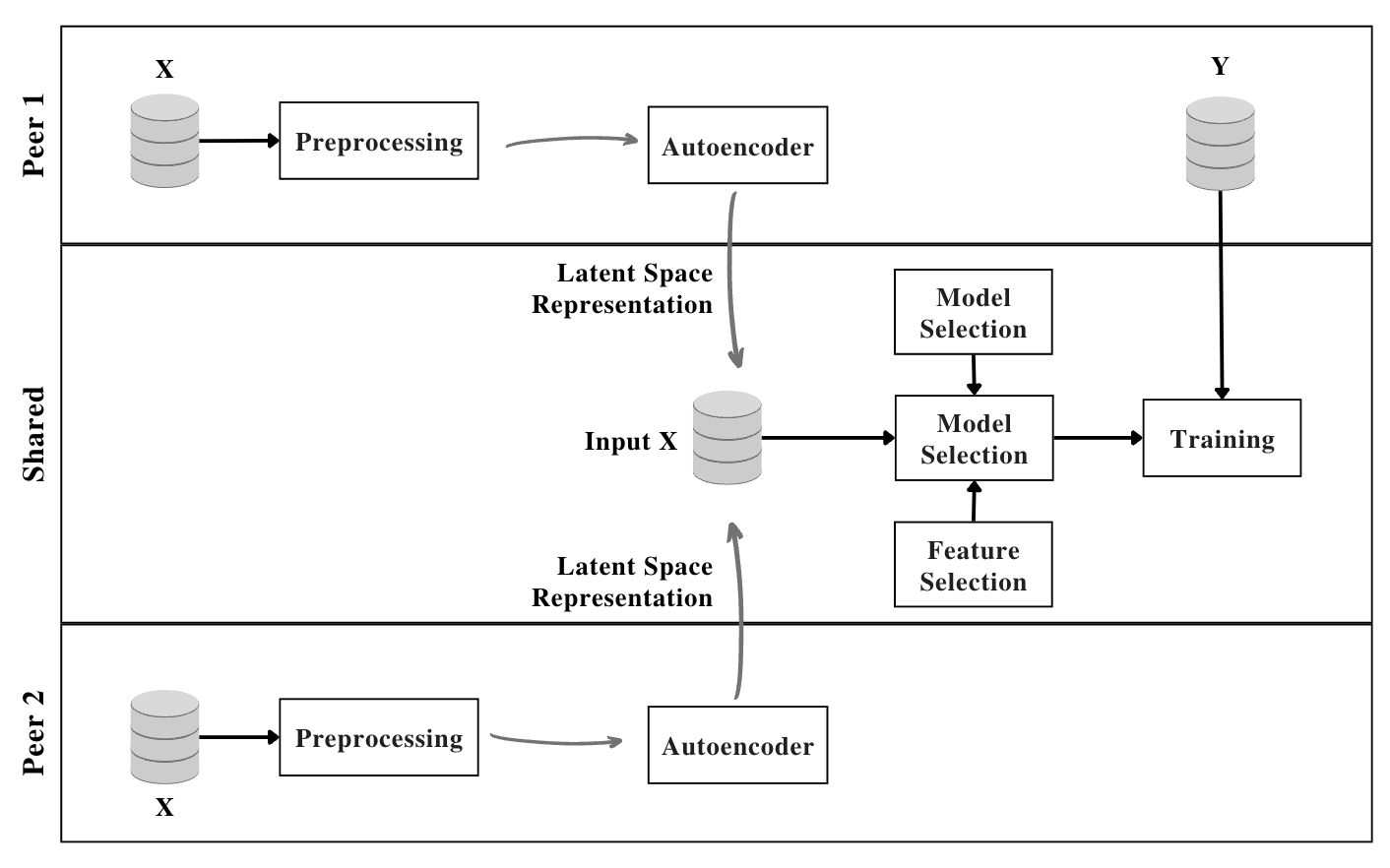
Privacy-preserving machine learning in data-sharing processes is an ever-critical task that enables collaborative training of Machine Learning (ML) models without the need to share the original data sources. It is especially relevant when an organization must assure that sensitive data remains private throughout the whole ML pipeline, i.e., training and inference phases. This paper presents an innovative framework that uses Representation Learning via autoencoders to generate privacy-preserving embedded data. Thus, organizations can share the data representation to increase machine learning models' performance in scenarios with more than one data source for a shared predictive downstream task.
翻译:数据分享过程中的隐私保护机器学习是一项至关重要的任务,它使得无需分享原始数据来源就可以对机器学习模型进行协作培训,当一个组织必须确保敏感数据在整个ML编审过程中,即培训和推论阶段,始终是保密的时,就特别相关。本文件提出了一个创新框架,利用自动算术者代表学习生成隐私保护嵌入数据。因此,各组织可以分享数据代表,以提高机器学习模型在多个数据源的假想中的性能,以共享的预测下游任务。