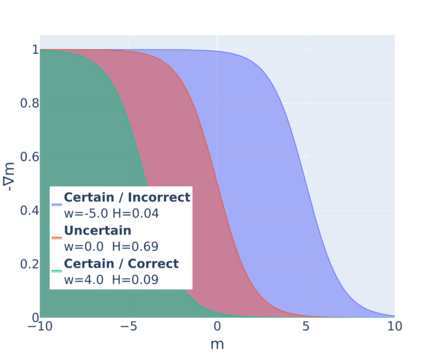
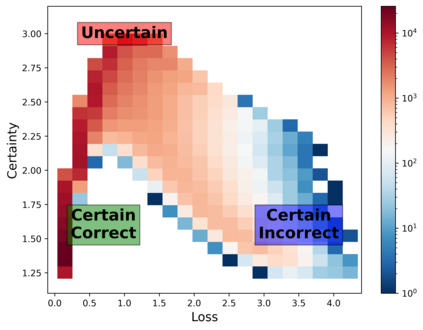
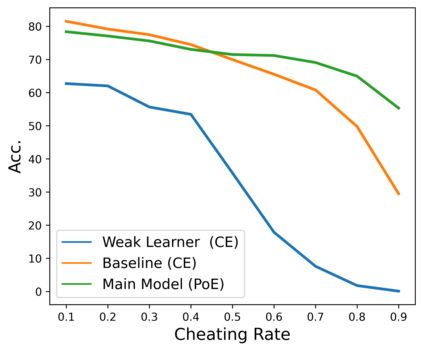
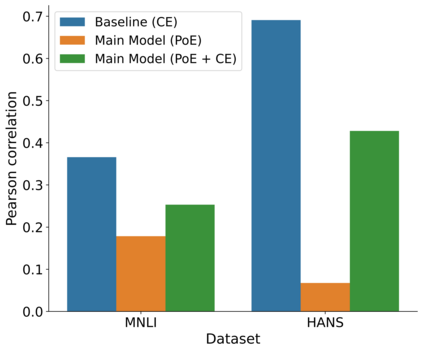
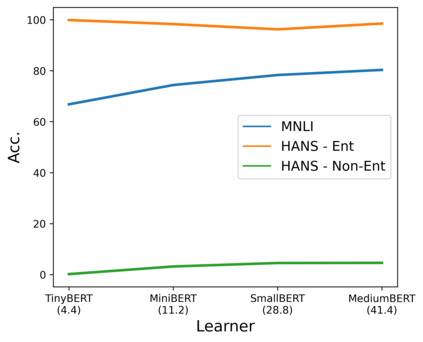
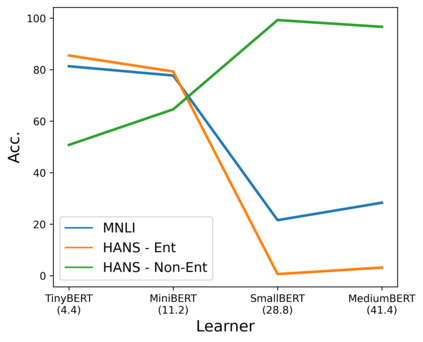
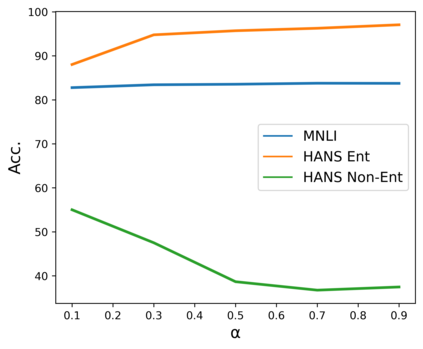
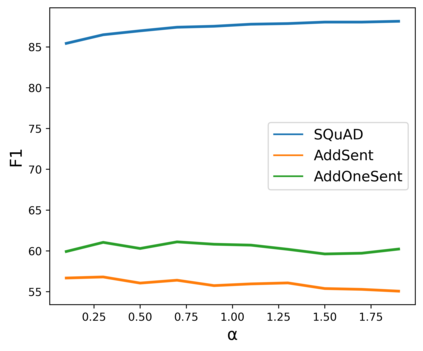
State-of-the-art natural language processing (NLP) models often learn to model dataset biases and surface form correlations instead of features that target the intended underlying task. Previous work has demonstrated effective methods to circumvent these issues when knowledge of the bias is available. We consider cases where the bias issues may not be explicitly identified, and show a method for training models that learn to ignore these problematic correlations. Our approach relies on the observation that models with limited capacity primarily learn to exploit biases in the dataset. We can leverage the errors of such limited capacity models to train a more robust model in a product of experts, thus bypassing the need to hand-craft a biased model. We show the effectiveness of this method to retain improvements in out-of-distribution settings even if no particular bias is targeted by the biased model.
翻译:最先进的自然语言处理(NLP)模型往往学会模拟数据集偏差和表面的相互关系,而不是针对预期的基本任务而设计的特征。以前的工作已经表明,在了解偏差时,可以有效地规避这些问题。我们考虑偏见问题可能没有被明确查明的案例,并展示一种培训模型的方法,以学会忽略这些有问题的相互关系。我们的方法依赖于这样一种观察,即能力有限的模型主要学会利用数据集中的偏见。我们可以利用这种有限能力模型的错误,在专家的产物中训练一个更强大的模型,从而绕过手动偏差模型的需要。我们展示了这种方法的有效性,即使偏差模型没有针对特定的偏差,在分配之外环境中保持改进。