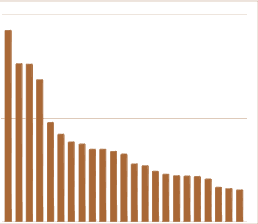
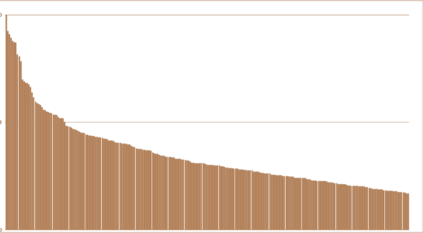
Though impressive performance has been achieved in specific visual realms (e.g. faces, dogs, and places), an omni-vision representation generalizing to many natural visual domains is highly desirable. But, existing benchmarks are biased and inefficient to evaluate the omni-vision representation -- these benchmarks either only include several specific realms, or cover most realms at the expense of subsuming numerous datasets that have extensive realm overlapping. In this paper, we propose Omni-Realm Benchmark (OmniBenchmark). It includes 21 realm-wise datasets with 7,372 concepts and 1,074,346 images. Without semantic overlapping, these datasets cover most visual realms comprehensively and meanwhile efficiently. In addition, we propose a new supervised contrastive learning framework, namely Relational Contrastive learning (ReCo), for a better omni-vision representation. Beyond pulling two instances from the same concept closer -- the typical supervised contrastive learning framework -- ReCo also pulls two instances from the same semantic realm closer, encoding the semantic relation between concepts, and facilitating omni-vision representation learning. We benchmark ReCo and other advances in omni-vision representation studies that are different in architectures (from CNNs to transformers) and in learning paradigms (from supervised learning to self-supervised learning) on OmniBenchmark. We illustrate the superior of ReCo to other supervised contrastive learning methods and reveal multiple practical observations to facilitate future research.
翻译:尽管在具体的视觉领域(如脸部、狗和地点)取得了令人印象深刻的业绩,但将全视代表面概括到许多自然视觉领域是十分可取的。但是,现有的基准有偏差而且效率低下,无法评价全视代表面 -- -- 这些基准要么只包括几个特定领域,或者覆盖大多数领域,而牺牲大量领域相互重叠的数据集。在本文中,我们提议Omni-Realm基准(OmniBenchmark),其中包括21个域间数据集,有7,372个概念和1,074,346个图像。在没有语义重叠的情况下,这些数据集全面而同时有效地覆盖大多数视觉领域。此外,我们提出一个新的受监督的对比性学习框架,即关系对比性学习(ReCU),除了从同一概念中更接近两个实例外,典型的监管性对比性学习框架 -- ReCo 还将同一语系的对比性框架分为两个实例,将概念之间的语义关系整合为概念间的关系,并便利将大多数视觉领域全面、同时有效地覆盖大多数视觉领域。此外,我们还提议一个新的受监管的自我学习结构中的自我学习。我们将其他学习的学习模式的系统内部结构中的学习模式中的学习系统。