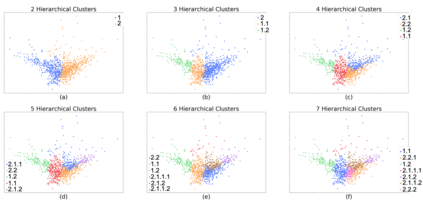
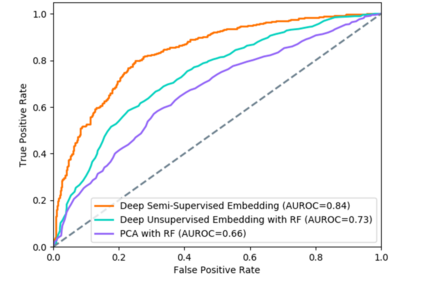
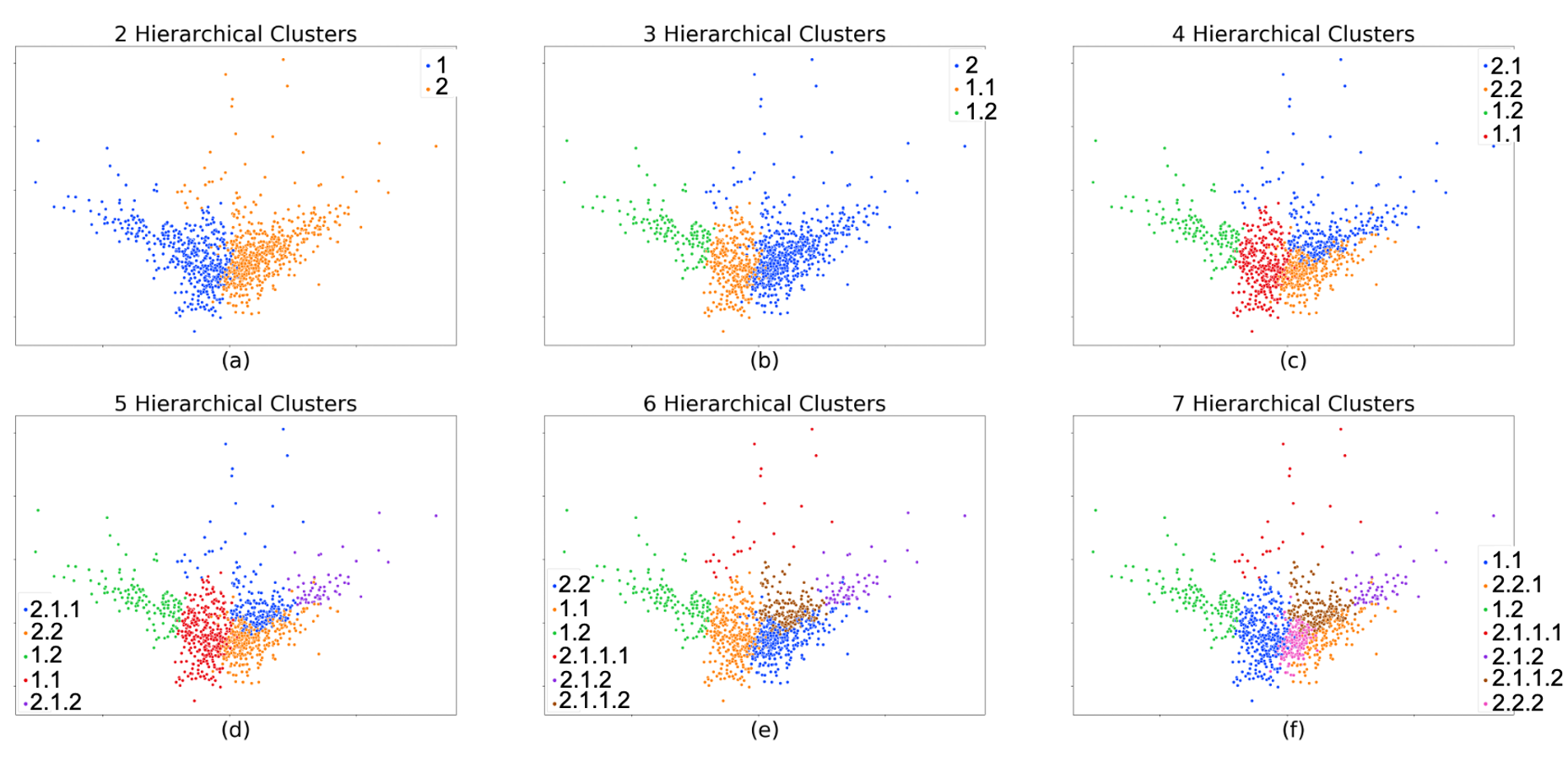
Determining phenotypes of diseases can have considerable benefits for in-hospital patient care and to drug development. The structure of high dimensional data sets such as electronic health records are often represented through an embedding of the data, with clustering methods used to group data of similar structure. If subgroups are known to exist within data, supervised methods may be used to influence the clusters discovered. We propose to extend deep embedded clustering to a semi-supervised deep embedded clustering algorithm to stratify subgroups through known labels in the data. In this work we apply deep semi-supervised embedded clustering to determine data-driven patient subgroups of heart failure from the electronic health records of 4,487 heart failure and control patients. We find clinically relevant clusters from an embedded space derived from heterogeneous data. The proposed algorithm can potentially find new undiagnosed subgroups of patients that have different outcomes, and, therefore, lead to improved treatments.
翻译:确定疾病的个人类型对住院病人护理和药物开发具有相当大的好处。电子健康记录等高维数据集的结构往往通过嵌入数据来体现,并采用集群方法对类似结构的数据进行分组。如果已知在数据中存在分组,则可以使用监督方法影响发现的分组。我们提议将深嵌入的集群扩展至半监督的深嵌入式分组算法,通过数据中已知的标签来将分组进行分层。在这项工作中,我们采用深半监督的嵌入式集群,从4 487个心脏衰竭和控制病人的电子健康记录中确定数据驱动的心衰竭病人分组。我们从一个从不同数据衍生的嵌入空间中找到与临床相关的分组。拟议的算法可能找到新的未诊断结果不同的患者分组,从而导致治疗的改善。