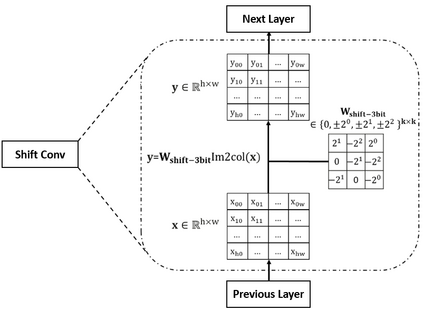
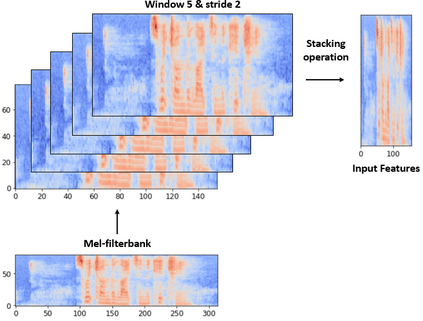
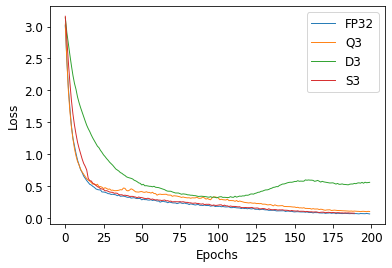
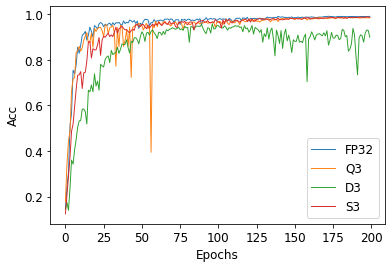
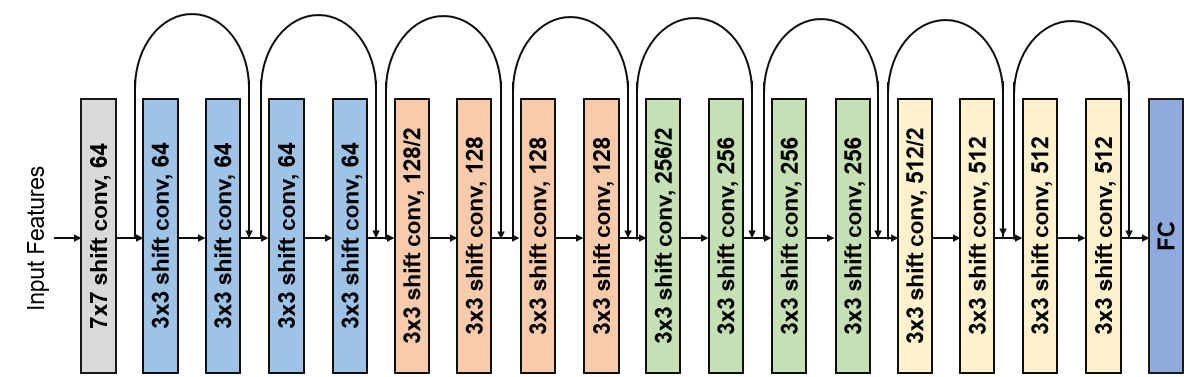
Deep neural networks (DNN) have achieved impressive success in multiple domains. Over the years, the accuracy of these models has increased with the proliferation of deeper and more complex architectures. Thus, state-of-the-art solutions are often computationally expensive, which makes them unfit to be deployed on edge computing platforms. In order to mitigate the high computation, memory, and power requirements of inferring convolutional neural networks (CNNs), we propose the use of power-of-two quantization, which quantizes continuous parameters into low-bit power-of-two values. This reduces computational complexity by removing expensive multiplication operations and with the use of low-bit weights. ResNet is adopted as the building block of our solution and the proposed model is evaluated on a spoken language understanding (SLU) task. Experimental results show improved performance for shift neural network architectures, with our low-bit quantization achieving 98.76 \% on the test set which is comparable performance to its full-precision counterpart and state-of-the-art solutions.
翻译:深神经网络(DNN)在多个领域取得了令人印象深刻的成功。多年来,这些模型的准确性随着更深、更复杂的结构的扩展而提高。因此,最先进的解决方案往往在计算上昂贵,因此不适合在边缘计算平台上部署。为了减轻计算、记忆和电流神经网络(CNN)的高要求,我们建议使用2个四分法,将连续参数量化为低位二分权值。这通过消除昂贵的倍增操作和使用低位权重来降低计算复杂性。ResNet被采纳为我们解决方案的建筑块,而拟议模型则根据口头语言理解(SLU)的任务进行评估。实验结果显示,随着我们低位四分法网络结构实现98.76 ⁇ 测试集的性能,该测试集的性能与其全精度对应方和状态解决方案相当。