
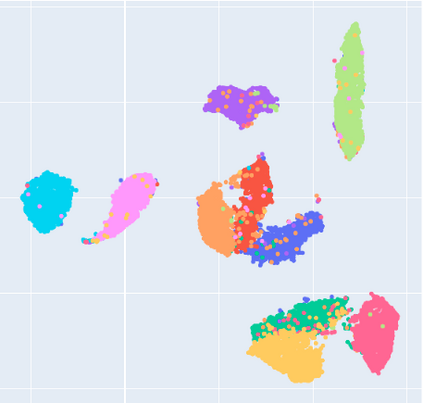
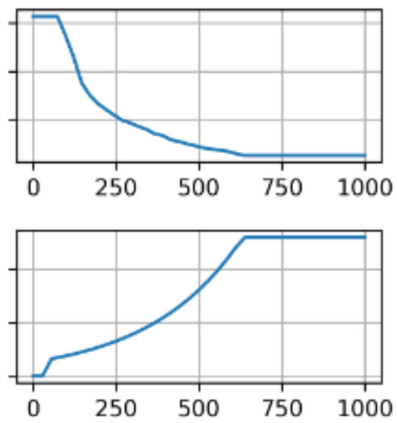
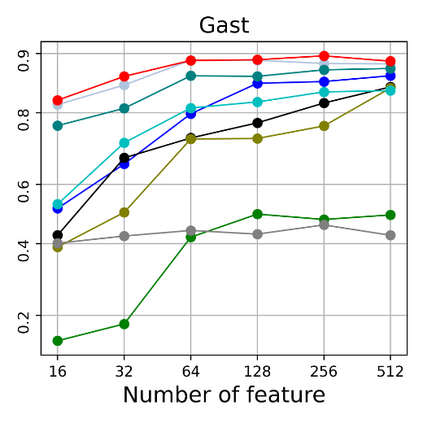
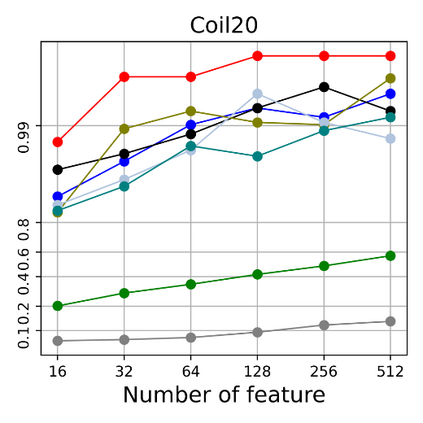
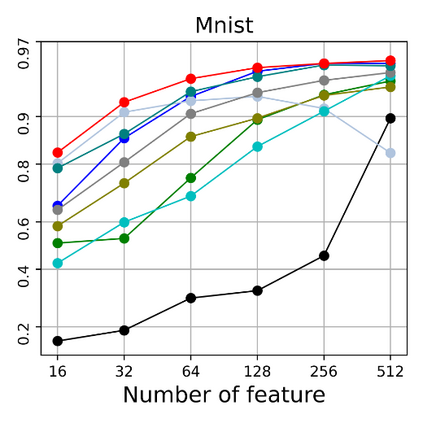
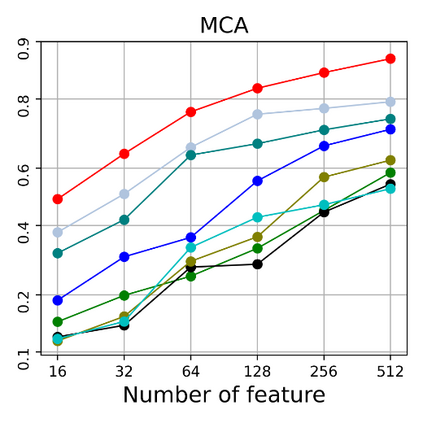
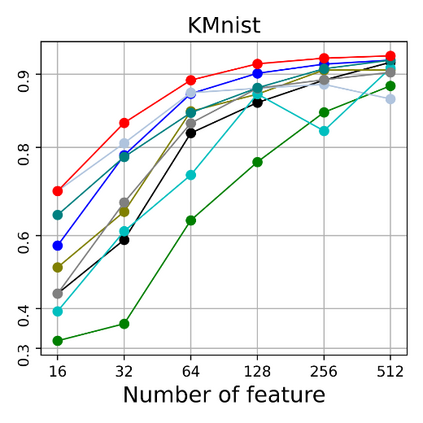
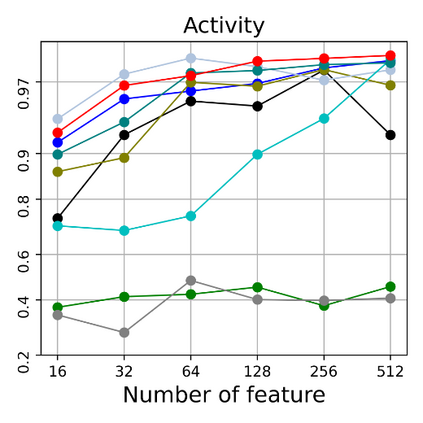
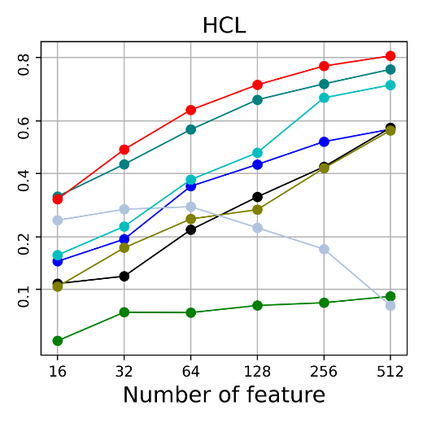
Dimensional reduction~(DR) maps high-dimensional data into a lower dimensions latent space with minimized defined optimization objectives. The DR method usually falls into feature selection~(FS) and feature projection~(FP). FS focuses on selecting a critical subset of dimensions but risks destroying the data distribution (structure). On the other hand, FP combines all the input features into lower dimensions space, aiming to maintain the data structure; but lacks interpretability and sparsity. FS and FP are traditionally incompatible categories; thus, they have not been unified into an amicable framework. We propose that the ideal DR approach combines both FS and FP into a unified end-to-end manifold learning framework, simultaneously performing fundamental feature discovery while maintaining the intrinsic relationships between data samples in the latent space. In this work, we develop a unified framework, Unified Dimensional Reduction Neural-network~(UDRN), that integrates FS and FP in a compatible, end-to-end way. We improve the neural network structure by implementing FS and FP tasks separately using two stacked sub-networks. In addition, we designed data augmentation of the DR process to improve the generalization ability of the method when dealing with extensive feature datasets and designed loss functions that can cooperate with the data augmentation. Extensive experimental results on four image and four biological datasets, including very high-dimensional data, demonstrate the advantages of DRN over existing methods~(FS, FP, and FS\&FP pipeline), especially in downstream tasks such as classification and visualization.
翻译:(DR) 将高维度数据映射成一个低维度潜藏空间,并尽量减少优化目标。DR方法通常包含特征选择-(FS) 和特征投影~(FP) 。 FS 侧重于选择一个关键的维度子集,但有破坏数据分布(结构)的风险。另一方面,FS 将所有输入特征整合到较低维度空间,目的是维护数据结构;但缺乏可解释性和宽度。FS 和FP 传统上是互不兼容的类别;因此,它们没有统一到一个友好的框架;我们建议理想的DR方法将FS和FP 合并成一个统一的端到端的多管间学习框架,同时进行基本特征发现,同时维护潜在空间数据样本之间的内在关系。在这项工作中,我们开发一个统一框架,将所有输入特性减少神经网络(UDRN) 整合到低维度空间和FS 。 我们用两个堆叠式的子网络分别执行FS和FS任务来改进神经网络结构结构结构结构。 此外,我们设计DR的数据增强基本特征,特别是直观性发现四级数据模型的升级能力,从而展示现有数据基础数据升级,从而展示基础数据模型的升级能力。
















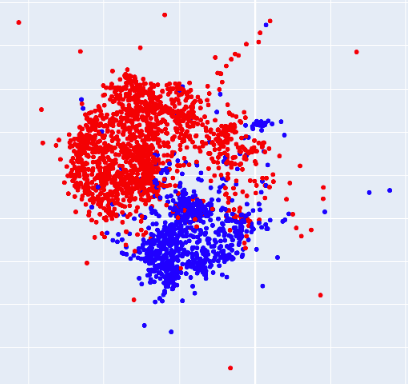
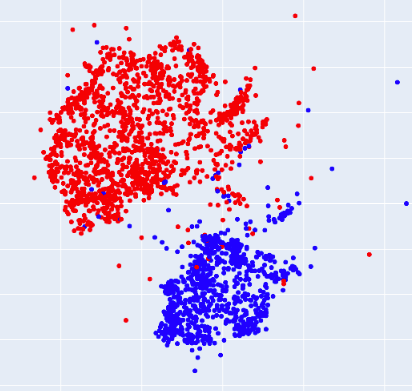
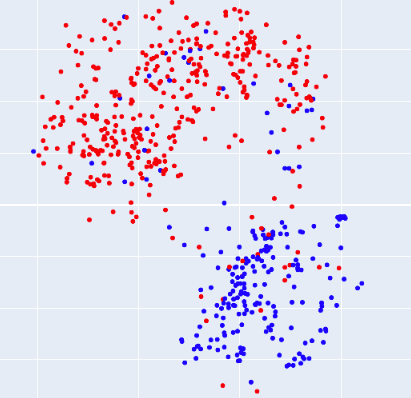
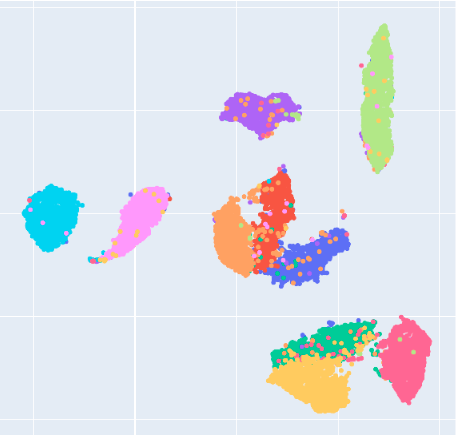
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


