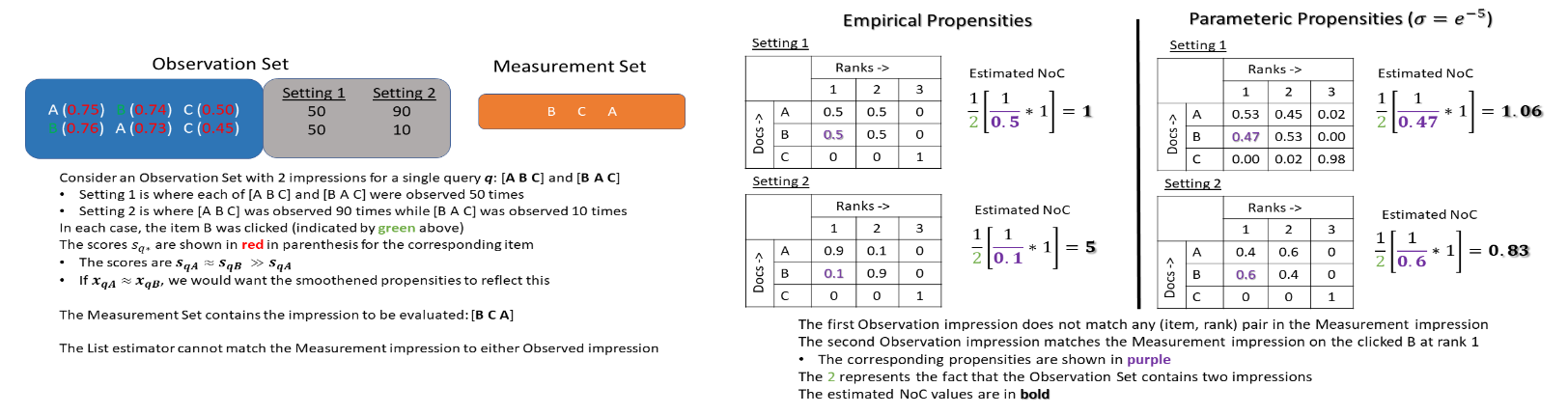
Search engines and recommendation systems attempt to continually improve the quality of the experience they afford to their users. Refining the ranker that produces the lists displayed in response to user requests is an important component of this process. A common practice is for the service providers to make changes (e.g. new ranking features, different ranking models) and A/B test them on a fraction of their users to establish the value of the change. An alternative approach estimates the effectiveness of the proposed changes offline, utilising previously collected clickthrough data on the old ranker to posit what the user behaviour on ranked lists produced by the new ranker would have been. A majority of offline evaluation approaches invoke the well studied inverse propensity weighting to adjust for biases inherent in logged data. In this paper, we propose the use of parametric estimates for these propensities. Specifically, by leveraging well known learning-to-rank methods as subroutines, we show how accurate offline evaluation can be achieved when the new rankings to be evaluated differ from the logged ones.
翻译:搜索引擎和建议系统试图不断提高用户的经验质量。 精炼根据用户要求编制列表的排位器是这一过程的一个重要组成部分。 一个常见的做法是服务供应商对用户的一小部分进行修改(例如新的排位特征、不同的排位模式)和A/B测试A/B,以确定变化的价值。 另一种方法估计了拟议离线变化的效果,利用以前在旧排位上收集的点击数据来显示新排位产生的排位列表上的用户行为。 大多数离线评价方法都引用了经过仔细研究的反向偏重权重来调整登录数据固有的偏差。 在本文件中,我们建议对这些偏差使用参数估计值。 具体地说,通过利用已知的学习到排位方法作为子路程,我们展示了当要评价的新排位与登录的排位不同时,如何实现准确的离线评价。