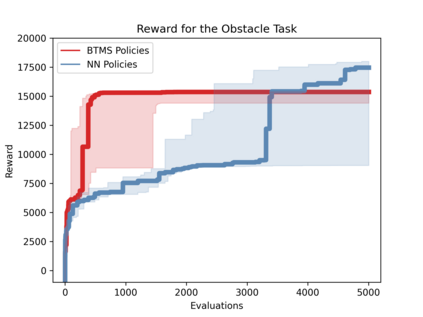
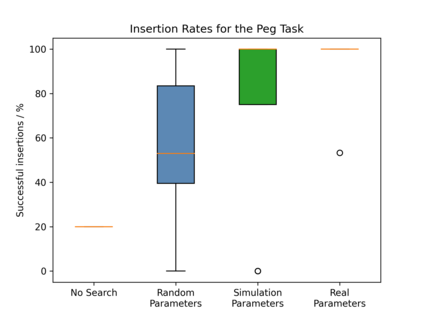
Reinforcement Learning (RL) is a powerful mathematical framework that allows robots to learn complex skills by trial-and-error. Despite numerous successes in many applications, RL algorithms still require thousands of trials to converge to high-performing policies, can produce dangerous behaviors while learning, and the optimized policies (usually modeled as neural networks) give almost zero explanation when they fail to perform the task. For these reasons, the adoption of RL in industrial settings is not common. Behavior Trees (BTs), on the other hand, can provide a policy representation that a) supports modular and composable skills, b) allows for easy interpretation of the robot actions, and c) provides an advantageous low-dimensional parameter space. In this paper, we present a novel algorithm that can learn the parameters of a BT policy in simulation and then generalize to the physical robot without any additional training. We leverage a physical simulator with a digital twin of our workstation, and optimize the relevant parameters with a black-box optimizer. We showcase the efficacy of our method with a 7-DOF KUKA-iiwa manipulator in a task that includes obstacle avoidance and a contact-rich insertion (peg-in-hole), in which our method outperforms the baselines.
翻译:强化学习(RL)是一个强大的数学框架,允许机器人通过试演学习复杂的技能。尽管在许多应用中取得了许多成功,但RL算法仍然需要数千次试验才能与高性能政策趋同,在学习过程中可以产生危险的行为,而优化政策(通常以神经网络为模型)在不完成任务时几乎没有解释。出于这些原因,在工业环境中采用RL并不常见。行为树(BTs)可以提供一种政策代表,即a)支持模块和可变技能,b)便于对机器人动作进行简单解释,c)提供一个有利的低维参数空间。在本文中,我们提出了一个新的算法,可以在模拟中学习BT政策的参数,然后在没有接受任何额外培训的情况下将参数推广到物理机器人。我们利用工作站的数码双对物理模拟器,用黑箱优化相关参数。我们用7-DOF KUKA-iworm 来展示我们方法的功效,用7-F KUKA-iroiorm-modestration(在任务中采用避免接触和超越基准)的方法。