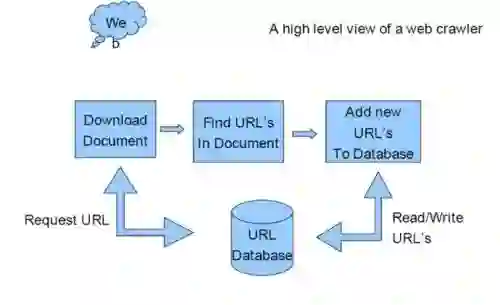
The web is today's primary publication medium, making web archiving an important activity for historical and analytical purposes. Web pages are increasingly interactive, resulting in pages that are increasingly difficult to archive. Client-side technologies (e.g., JavaScript) enable interactions that can potentially change the client-side state of a representation. We refer to representations that load embedded resources via JavaScript as deferred representations. It is difficult to archive all of the resources in deferred representations and the result is archives with web pages that are either incomplete or that erroneously load embedded resources from the live web. We propose a method of discovering and crawling deferred representations and their descendants (representation states that are only reachable through client-side events). We adapt the Dincturk et al. Hypercube model to construct a model for archiving descendants, and we measure the number of descendants and requisite embedded resources discovered in a proof-of-concept crawl. Our approach identified an average of 38.5 descendants per seed URI crawled, 70.9% of which are reached through an onclick event. This approach also added 15.6 times more embedded resources than Heritrix to the crawl frontier, but at a rate that was 38.9 times slower than simply using Heritrix. We show that our dataset has two levels of descendants. We conclude with proposed crawl policies and an analysis of the storage requirements for archiving descendants.
翻译:网络是今天的主要出版媒介,使网络归档成为历史和分析方面的重要活动。网页日益互动,导致网页越来越难存档。客户端技术(例如JavaScript)使得互动有可能改变代表方的客户端状态。我们指的是通过JavaScript将嵌入的资源作为延后陈述的形式,通过JavaScript装载嵌入的资源。我们的方法是将所有资源存档在推迟的表述中,结果就是将所有资源存档在网页上,这些网页要么不完整,要么错误地从现场网上输入了嵌入的资源。我们提出了一种发现和爬入推迟的代表及其后代的方法(代表国只能通过客户端活动达到)。我们调整了Dincturk 和 al. 超立方模型,以构建一个归档后代的模式,我们用Javas-Script 来测量后代的数量和在概念测试中发现的嵌入资源。我们的方法确定,每个种子的后代平均38.5个后代,其中70.9%是通过点击活动获得的。这个方法还增加了15.6倍于Hiritrix的嵌入资源,但我们用38个时期的顺序分析结果显示,我们提出的递增速度为38次。