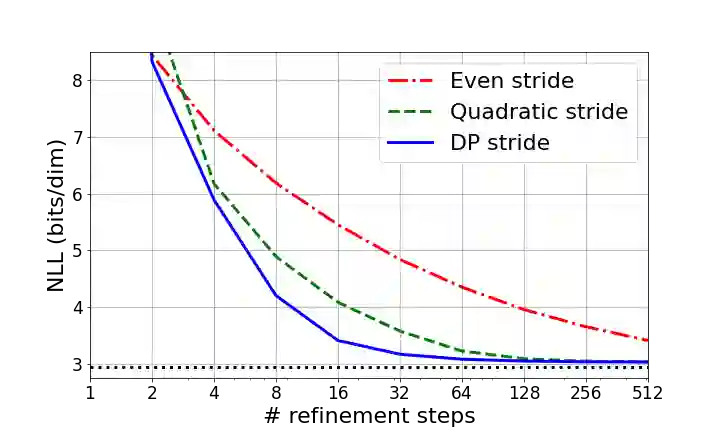
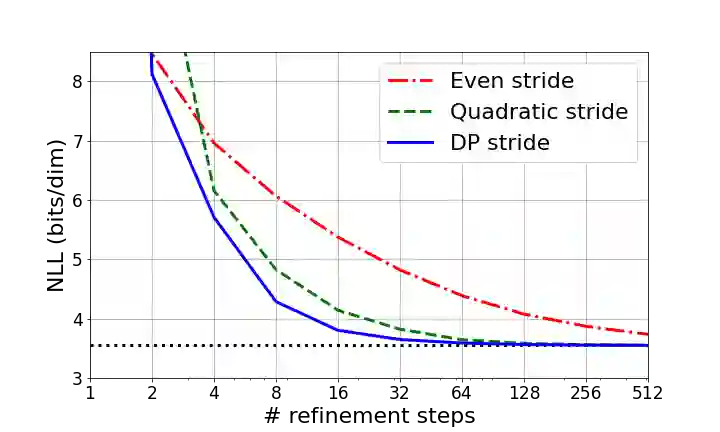
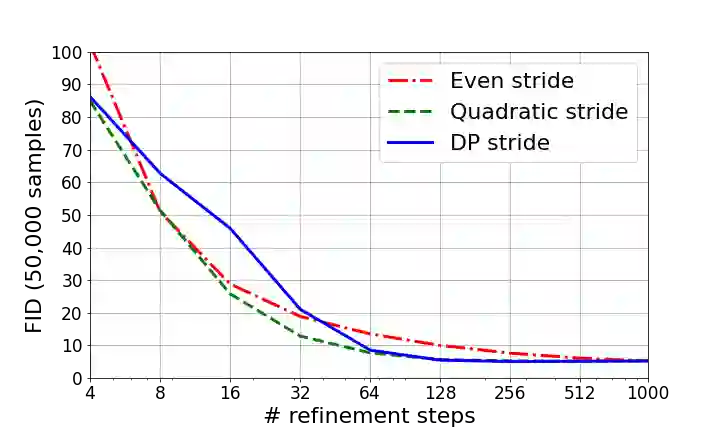
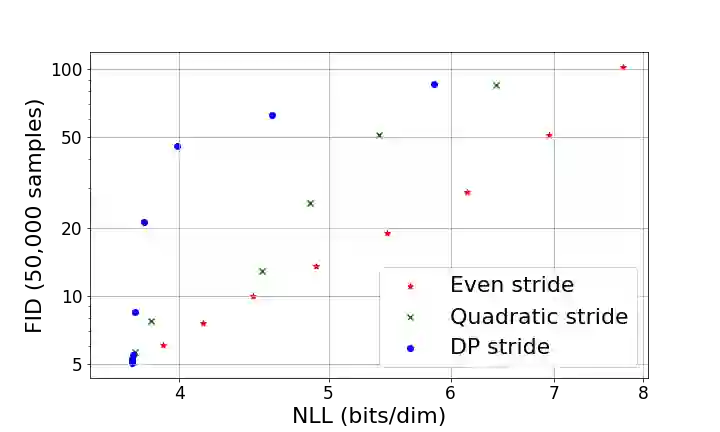
Denoising Diffusion Probabilistic Models (DDPMs) have emerged as a powerful family of generative models that can yield high-fidelity samples and competitive log-likelihoods across a range of domains, including image and speech synthesis. Key advantages of DDPMs include ease of training, in contrast to generative adversarial networks, and speed of generation, in contrast to autoregressive models. However, DDPMs typically require hundreds-to-thousands of steps to generate a high fidelity sample, making them prohibitively expensive for high dimensional problems. Fortunately, DDPMs allow trading generation speed for sample quality through adjusting the number of refinement steps as a post process. Prior work has been successful in improving generation speed through handcrafting the time schedule by trial and error. We instead view the selection of the inference time schedules as an optimization problem, and introduce an exact dynamic programming algorithm that finds the optimal discrete time schedules for any pre-trained DDPM. Our method exploits the fact that ELBO can be decomposed into separate KL terms, and given any computation budget, discovers the time schedule that maximizes the training ELBO exactly. Our method is efficient, has no hyper-parameters of its own, and can be applied to any pre-trained DDPM with no retraining. We discover inference time schedules requiring as few as 32 refinement steps, while sacrificing less than 0.1 bits per dimension compared to the default 4,000 steps used on ImageNet 64x64 [Ho et al., 2020; Nichol and Dhariwal, 2021].
翻译:DDPM模式(DDPMs)已经成为一个强大的基因模型组合,能够产生高纤维样本和在包括图像和语言合成在内的一系列领域具有竞争力的逻辑相似性。DDPM机制的主要优势包括:培训的便利性(相对于基因对抗网络而言)和生成速度(相对于自动递减模式而言) 。然而,DDPMS通常需要数百至千个步骤来生成高忠诚样本,因此对于高维度问题来说,这些样本成本太高。幸运的是,DDPMS允许通过调整改进步骤的数量来提高样本质量的贸易生成速度,作为后继过程。以前的工作成功地通过手工制作时间表和错误来改进了生成速度。我们把选择发酵时间表视为一个优化问题,并引入一个精确的动态编程算法,找到任何经过预先训练的DDPM(DDPM) 之前的最佳离散时间时间表。 我们的方法利用了ELBO可以分解为不同的 KL条件,并且考虑到任何计算预算的计算方法,在比比的升级预算中,比比的更精细的时间表更精确地发现,我们使用的是使用的是标准标准。