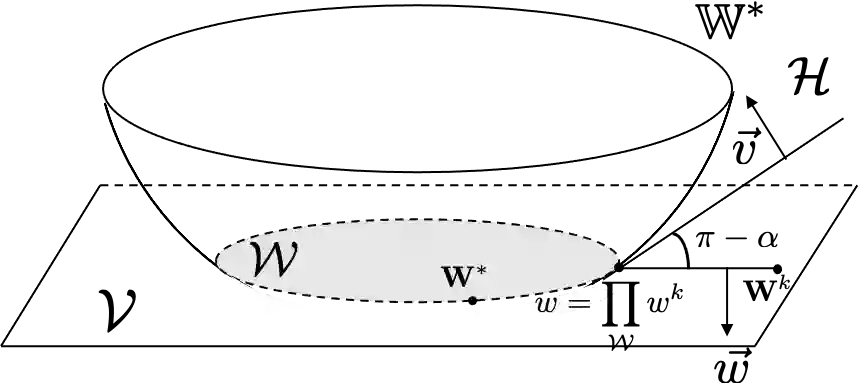
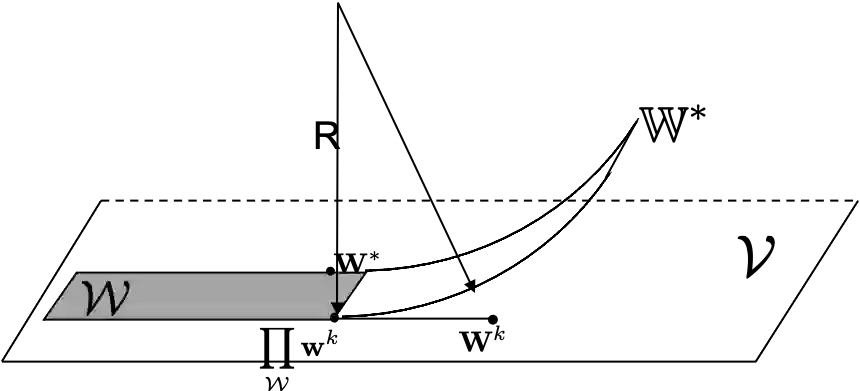
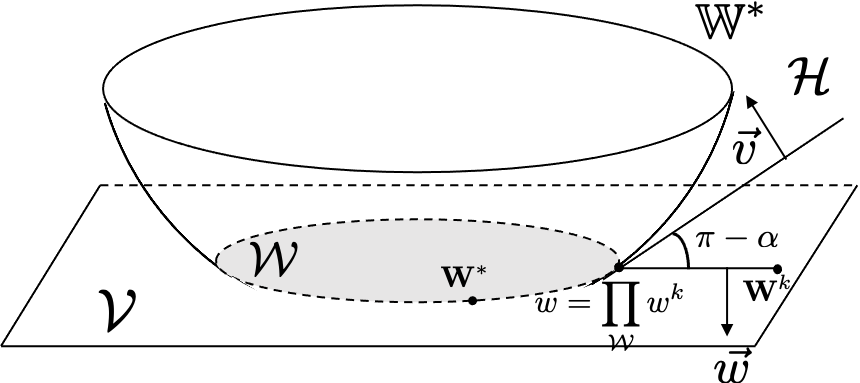
We study multi-objective reinforcement learning (RL) where an agent's reward is represented as a vector. In settings where an agent competes against opponents, its performance is measured by the distance of its average return vector to a target set. We develop statistically and computationally efficient algorithms to approach the associated target set. Our results extend Blackwell's approachability theorem (Blackwell, 1956) to tabular RL, where strategic exploration becomes essential. The algorithms presented are adaptive; their guarantees hold even without Blackwell's approachability condition. If the opponents use fixed policies, we give an improved rate of approaching the target set while also tackling the more ambitious goal of simultaneously minimizing a scalar cost function. We discuss our analysis for this special case by relating our results to previous works on constrained RL. To our knowledge, this work provides the first provably efficient algorithms for vector-valued Markov games and our theoretical guarantees are near-optimal.
翻译:我们研究多目标强化学习(RL),其中代理商的奖赏作为矢量。在代理商与对手竞争的环境下,其表现以平均返回矢量到目标集的距离来衡量。我们开发了统计和计算效率的算法,以接近相关目标集。我们的结果将Blackwell的可接近性理论(Blackwell,1956年)扩展为表格式RL,其中战略探索变得至关重要。所提出的算法是适应性的;即使没有Blackwell的可接近性条件,它们的保证也维持不变。如果反对者使用固定政策,我们就会提高接近既定目标的速度,同时解决同时尽量减少一个天平成本功能这一更宏伟的目标。我们讨论我们对这一特殊案例的分析,将我们的结果与以往关于受限制的矢量的RL的工程联系起来。根据我们的知识,这项工作为矢量值的Markov游戏提供了第一个可实现效率的算法,我们的理论保证是接近最佳的。