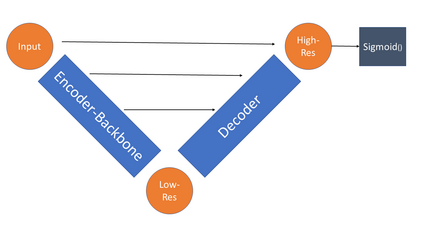
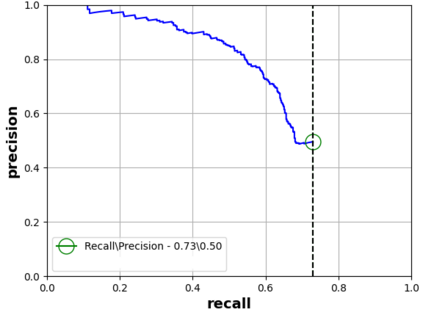
This paper addresses the problem of defect segmentation in semiconductor manufacturing. The input of our segmentation is a scanning-electron-microscopy (SEM) image of the candidate defect region. We train a U-net shape network to segment defects using a dataset of clean background images. The samples of the training phase are produced automatically such that no manual labeling is required. To enrich the dataset of clean background samples, we apply defect implant augmentation. To that end, we apply a copy-and-paste of a random image patch in the clean specimen. To improve the robustness of the unlabeled data scenario, we train the features of the network with unsupervised learning methods and loss functions. Our experiments show that we succeed to segment real defects with high quality, even though our dataset contains no defect examples. Our approach performs accurately also on the problem of supervised and labeled defect segmentation.
翻译:本文涉及半导体制造中的缺陷分解问题。 我们的分解输入是候选缺陷区域的扫描- 电子- 微镜( SEM) 图像。 我们用干净背景图像数据集培训一个 Unet 形状网络, 以分解缺陷。 培训阶段的样本自动生成, 无需人工标签。 为了丰富清洁背景样本的数据集, 我们应用了缺陷植入增强。 为此, 我们应用了一个随机图像补丁的复制版和粘贴版, 用于清洁样本中。 为了改进未加标签的数据的稳健性, 我们用不受监督的学习方法和损失功能来培训网络的特征。 我们的实验显示, 我们成功地将真正的缺陷分解出高质量的, 尽管我们的数据集没有瑕疵示例。 我们的方法也精确地处理监管和标签缺陷分解的问题。