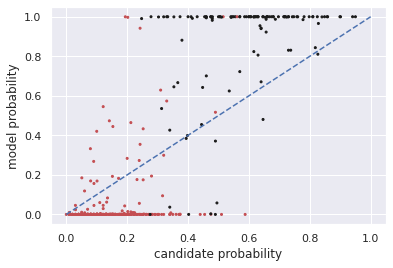
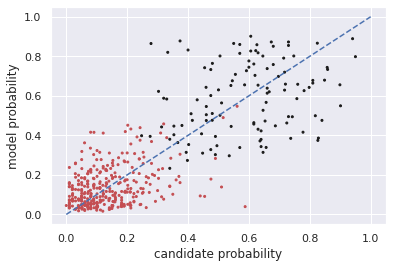
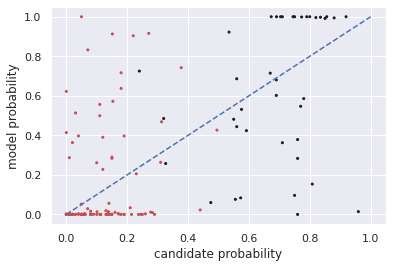
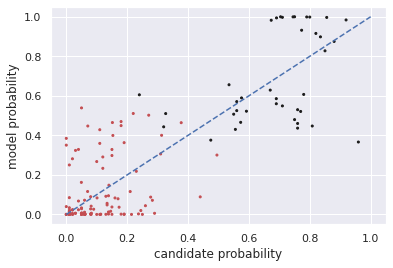
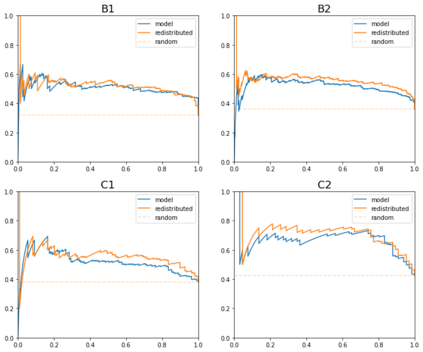
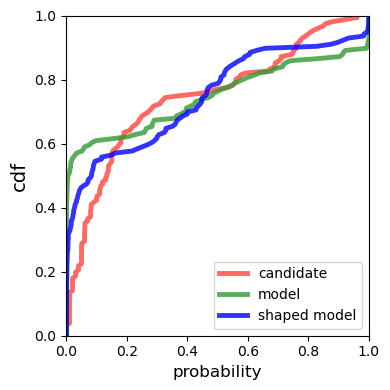
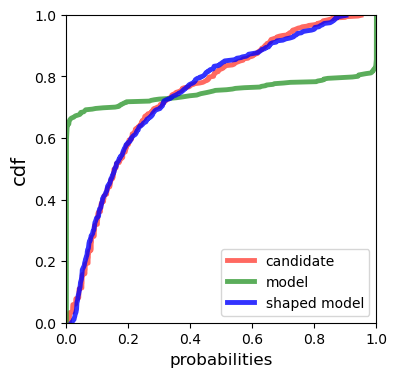
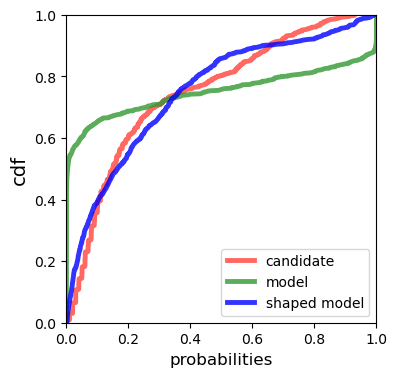
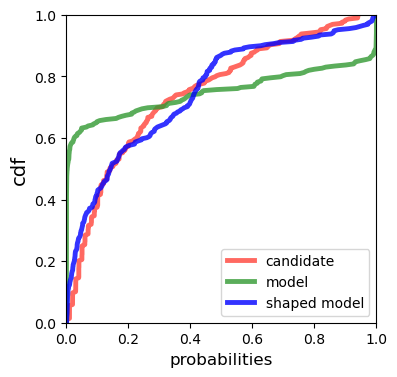
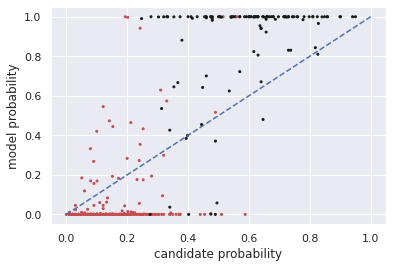
Multiple choice exams are widely used to assess candidates across a diverse range of domains and tasks. To moderate question quality, newly proposed questions often pass through pre-test evaluation stages before being deployed into real-world exams. Currently, this evaluation process is manually intensive, which can lead to time lags in the question development cycle. Streamlining this process via automation can significantly enhance efficiency, however, there's a current lack of datasets with adequate pre-test analysis information. In this paper we analyse the Cambridge Multiple-Choice Questions Reading Dataset; a multiple-choice comprehension dataset of questions at different target levels, with corresponding candidate selection distributions. We introduce the task of candidate distribution matching, propose several evaluation metrics for the task, and demonstrate that automatic systems trained on RACE++ can be leveraged as baselines for our task. We further demonstrate that these automatic systems can be used for practical pre-test evaluation tasks such as detecting underperforming distractors, where our detection systems can automatically identify poor distractors that few candidates select.
翻译:暂无翻译