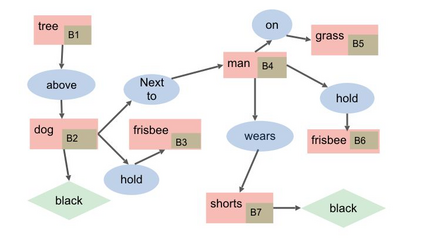
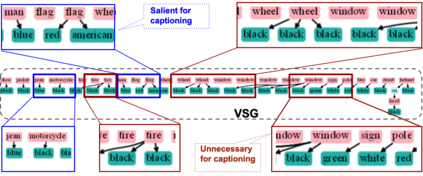
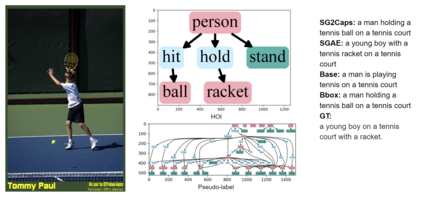
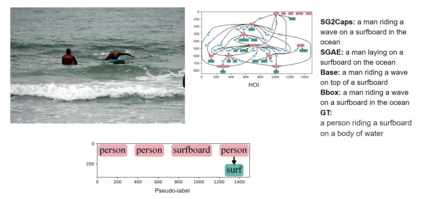
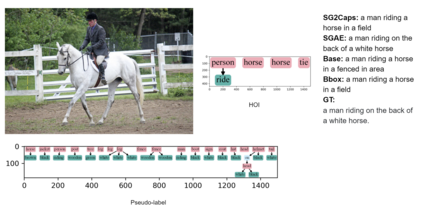
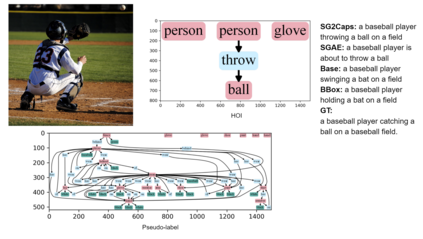
The mainstream image captioning models rely on Convolutional Neural Network (CNN) image features with an additional attention to salient regions and objects to generate captions via recurrent models. Recently, scene graph representations of images have been used to augment captioning models so as to leverage their structural semantics, such as object entities, relationships and attributes. Several studies have noted that naive use of scene graphs from a black-box scene graph generator harms image caption-ing performance, and scene graph-based captioning mod-els have to incur the overhead of explicit use of image features to generate decent captions. Addressing these challenges, we propose a framework, SG2Caps, that utilizes only the scene graph labels for competitive image caption-ing performance. The basic idea is to close the semantic gap between two scene graphs - one derived from the input image and the other one from its caption. In order to achieve this, we leverage the spatial location of objects and the Human-Object-Interaction (HOI) labels as an additional HOI graph. Our framework outperforms existing scene graph-only captioning models by a large margin (CIDEr score of 110 vs 71) indicating scene graphs as a promising representation for image captioning. Direct utilization of the scene graph labels avoids expensive graph convolutions over high-dimensional CNN features resulting in 49%fewer trainable parameters.
翻译:主流图像字幕模型依赖于进化神经网络(CNN)图像特征,更多关注突出区域和对象,以便通过重复式模型生成字幕。最近,图像的场景图示演示用于增加字幕模型,以利用其结构语义,如物体实体、关系和属性等。一些研究指出,黑盒图像图形生成方的场景图过于天真地地使用图像图会损害图像字幕性能,基于场景图示说明模式的模型将产生一个清晰使用图像特征生成像样字幕的图解。应对这些挑战时,我们提议了一个框架,即SG2Caps,仅使用场景图示标签进行竞争性图像说明性表现。基本想法是缩小两个场景图之间的语义差距,其中一个来自输入方位图像,另一个来自其标题。为了实现这一目标,我们将天体空间位置和人-直径插图(HOI)标签作为附加的HOI图表。我们的框架比现有的只用场景图示性图解的图示性图示性图示性图象模型更像性地显示高的图位数。