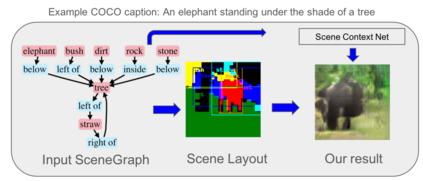
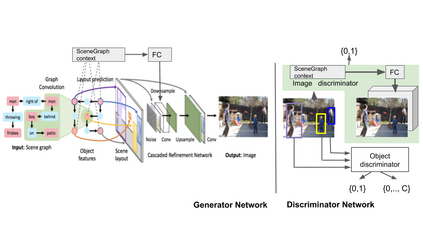
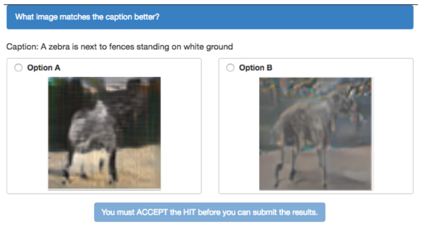
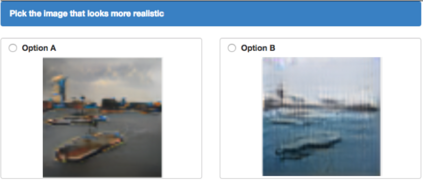
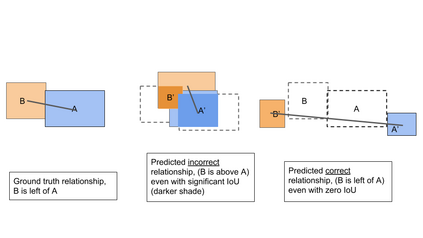
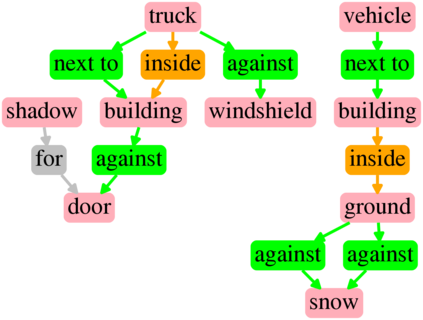
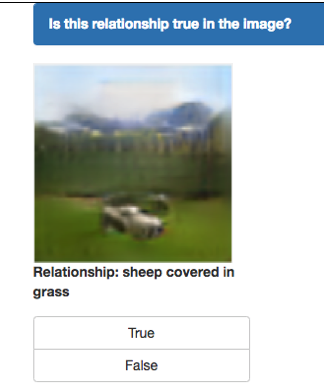
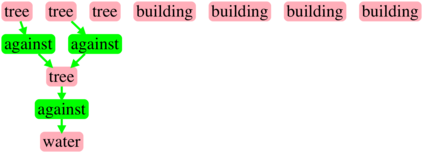
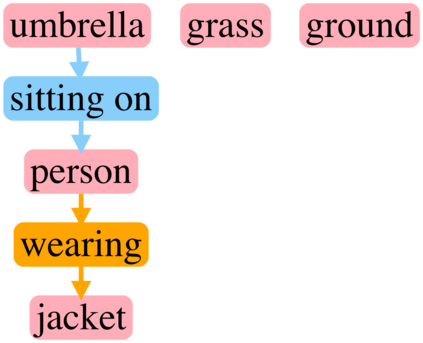
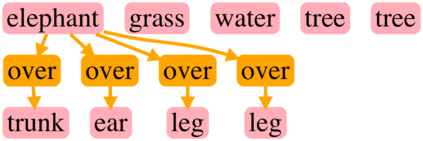
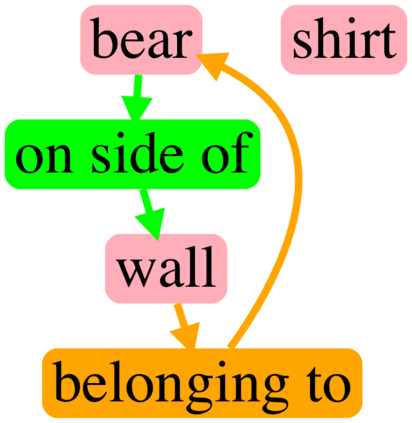
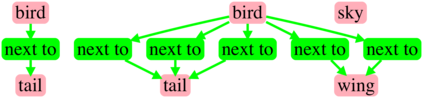
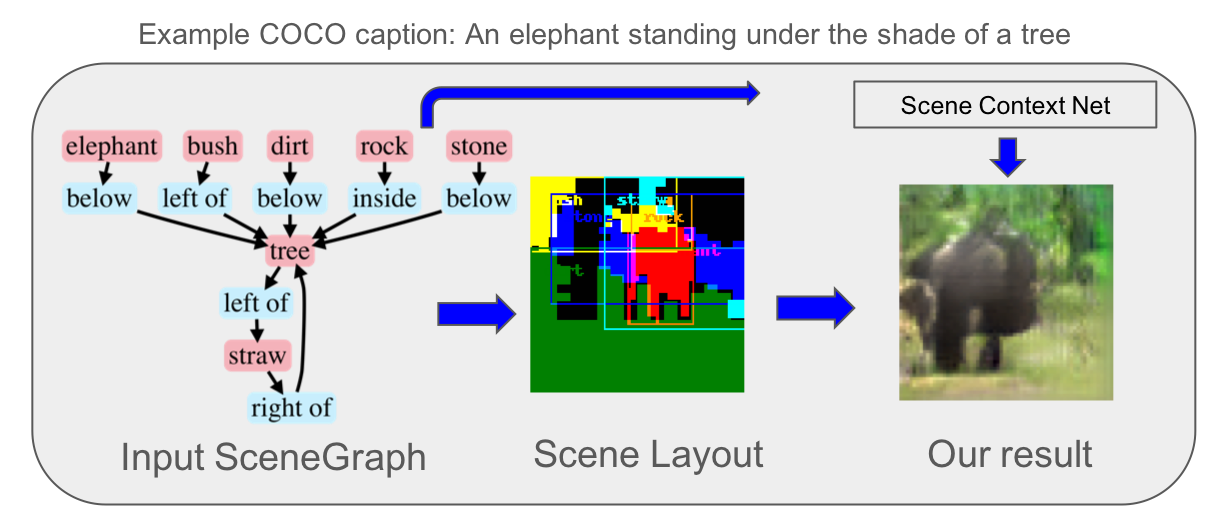
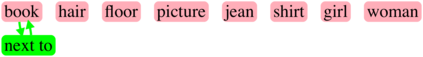Generating realistic images from scene graphs asks neural networks to be able to reason about object relationships and compositionality. As a relatively new task, how to properly ensure the generated images comply with scene graphs or how to measure task performance remains an open question. In this paper, we propose to harness scene graph context to improve image generation from scene graphs. We introduce a scene graph context network that pools features generated by a graph convolutional neural network that are then provided to both the image generation network and the adversarial loss. With the context network, our model is trained to not only generate realistic looking images, but also to better preserve non-spatial object relationships. We also define two novel evaluation metrics, the relation score and the mean opinion relation score, for this task that directly evaluate scene graph compliance. We use both quantitative and qualitative studies to demonstrate that our pro-posed model outperforms the state-of-the-art on this challenging task.
翻译:从场景图中生成现实图像,要求神经网络能够解释对象关系和构成性。作为一个相对较新的任务,如何适当确保生成的图像符合场景图或如何测量任务性能仍是一个未决问题。在本文件中,我们提议利用场景图背景来改进从场景图中生成图像的情况。我们引入一个场景图背景网络,将图象革命性神经网络生成的特征汇集在一起,然后提供给图像生成网络和对抗性损失。在场景网络中,我们的模型经过培训,不仅能够产生现实的图像,而且能够更好地保护非空间对象关系。我们还为直接评估场景图合规性的任务确定了两个新的评价指标,即关系评分和平均意见关系评分。我们利用定量和定性研究来证明我们所支持的模型在这项挑战性任务上超过了状态。