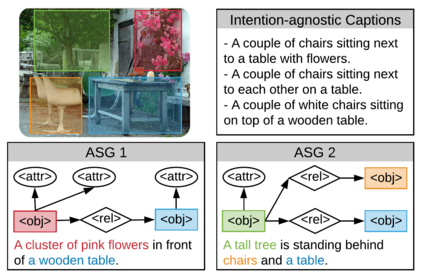
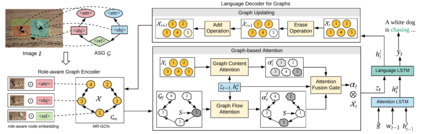
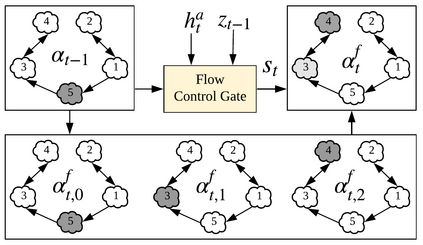
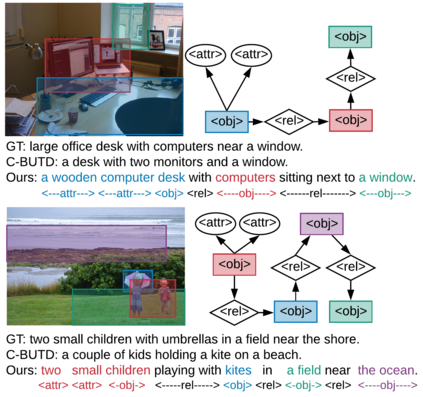
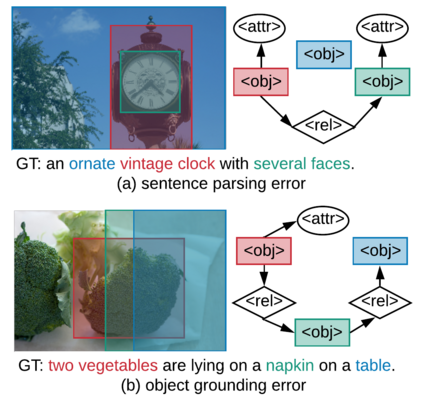
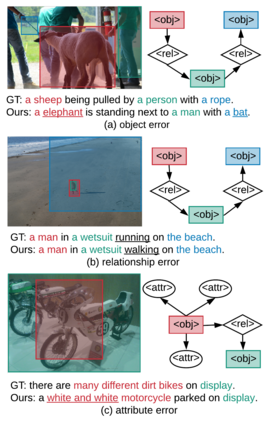
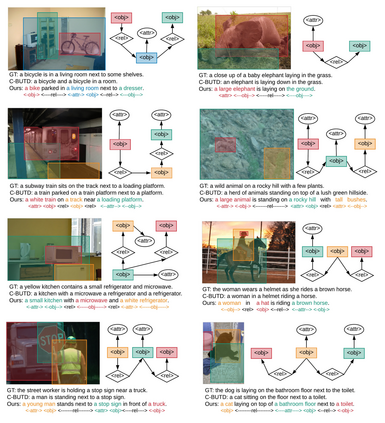
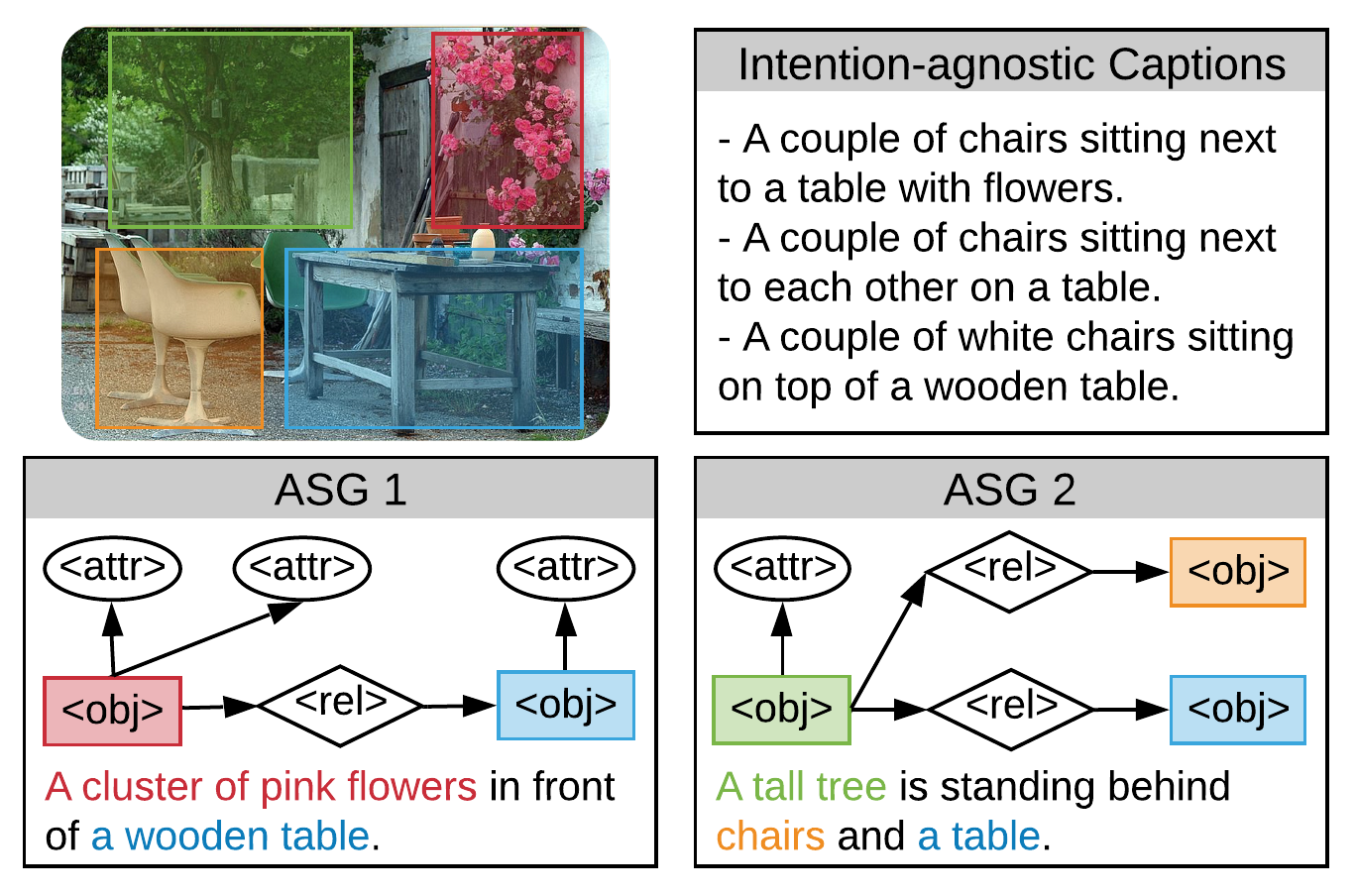
Humans are able to describe image contents with coarse to fine details as they wish. However, most image captioning models are intention-agnostic which can not generate diverse descriptions according to different user intentions initiatively. In this work, we propose the Abstract Scene Graph (ASG) structure to represent user intention in fine-grained level and control what and how detailed the generated description should be. The ASG is a directed graph consisting of three types of \textbf{abstract nodes} (object, attribute, relationship) grounded in the image without any concrete semantic labels. Thus it is easy to obtain either manually or automatically. From the ASG, we propose a novel ASG2Caption model, which is able to recognise user intentions and semantics in the graph, and therefore generate desired captions according to the graph structure. Our model achieves better controllability conditioning on ASGs than carefully designed baselines on both VisualGenome and MSCOCO datasets. It also significantly improves the caption diversity via automatically sampling diverse ASGs as control signals.
翻译:人类可以随意用粗略和细细的细节描述图像内容。 然而, 多数图像字幕模型都是意图的不可知性模型, 无法根据不同用户的主动意图生成不同的描述。 在此工作中, 我们提议了抽象场景图( ASG) 结构, 以细微的分层显示用户的意图, 并控制生成的描述应该如何详细。 ASG 是一张定向图, 由三种类型的 \ textb{ abtract nodes} ( 对象、属性、 关系) 组成, 以图像为基础, 没有任何具体的语义标签。 因此很容易手动或自动获取。 我们从 ASG 中提出一个新的 ASG2 Caption 模型, 能够识别图形中的用户意图和语义, 从而根据图形结构生成想要的文字。 我们的模型在ASGs上实现更好的可控性调控性, 而不是在VevisGenome 和 MSCOCO 数据集上精心设计的基线。 它还通过自动取样不同的 ASG 来显著改善字幕的多样性 。