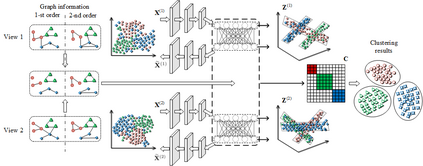
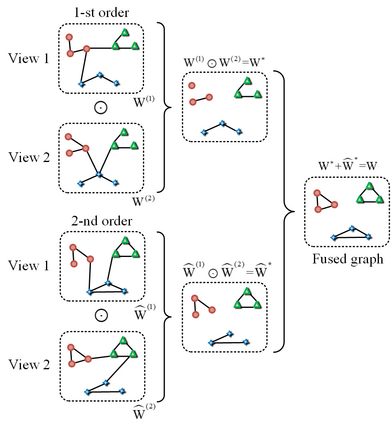
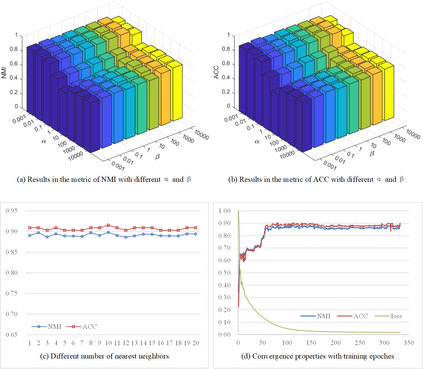
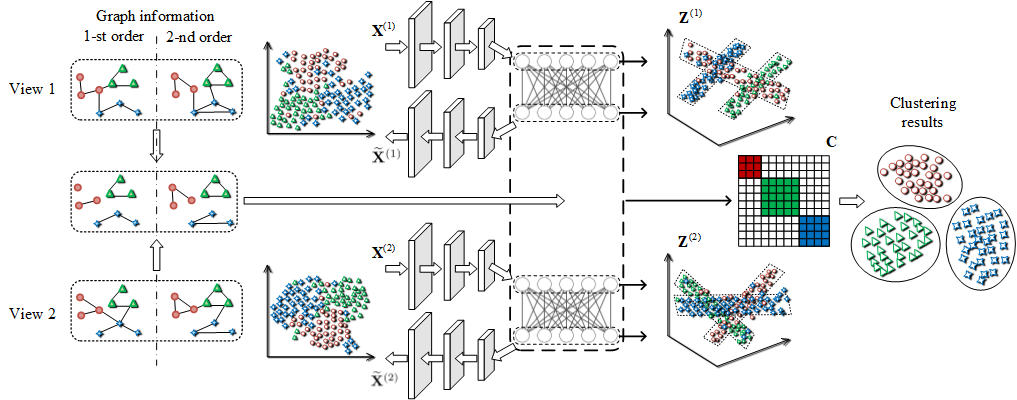
This study investigates the problem of multi-view subspace clustering, the goal of which is to explore the underlying grouping structure of data collected from different fields or measurements. Since data do not always comply with the linear subspace models in many real-world applications, most existing multi-view subspace clustering methods that based on the shallow linear subspace models may fail in practice. Furthermore, underlying graph information of multi-view data is always ignored in most existing multi-view subspace clustering methods. To address aforementioned limitations, we proposed the novel multi-view subspace clustering networks with local and global graph information, termed MSCNLG, in this paper. Specifically, autoencoder networks are employed on multiple views to achieve latent smooth representations that are suitable for the linear assumption. Simultaneously, by integrating fused multi-view graph information into self-expressive layers, the proposed MSCNLG obtains the common shared multi-view subspace representation, which can be used to get clustering results by employing the standard spectral clustering algorithm. As an end-to-end trainable framework, the proposed method fully investigates the valuable information of multiple views. Comprehensive experiments on six benchmark datasets validate the effectiveness and superiority of the proposed MSCNLG.
翻译:本研究调查了多视图子空间集群问题,其目的是探索从不同领域或测量收集的数据的基本分组结构;由于数据并不总是与许多现实世界应用中线性子空间模型一致,基于浅线性子空间模型的大多数现有多视图子空间集群方法在实践中可能失败;此外,在大多数现有的多视图子空间集群方法中,多视图数据的基本图形信息总是被忽视;为解决上述局限性,我们提议采用本文件中称为MSCNLG的本地和全球图形信息的新颖多视图子空间集群网络。具体地说,自动编码网络采用多种观点,以实现适合线性假设的潜在平稳表达。同时,通过将集成的多视图图形信息纳入自我表达层,拟议的MSCNLG获得了共同的多视图子空间代表制,可通过使用标准频谱组合算法获得组合结果。作为端对端培训的框架,拟议的方法充分调查了多视图的宝贵信息。关于六个基准数据组的全面实验验证了MSG的有效性和优越性。