分布式并行架构Ray介绍
1. Overview
Ray is a fast and simple framework for building and running distributed applications. The same code can be run on a single machine to achieve efficient multiprocessing, and it can be used on a cluster for large computations.
2. Connecting to Ray
There are two ways that a Ray script can be initiated. It can either be run in a standalone fashion or it can be connect to an existing Ray cluster.
Running Ray standalone
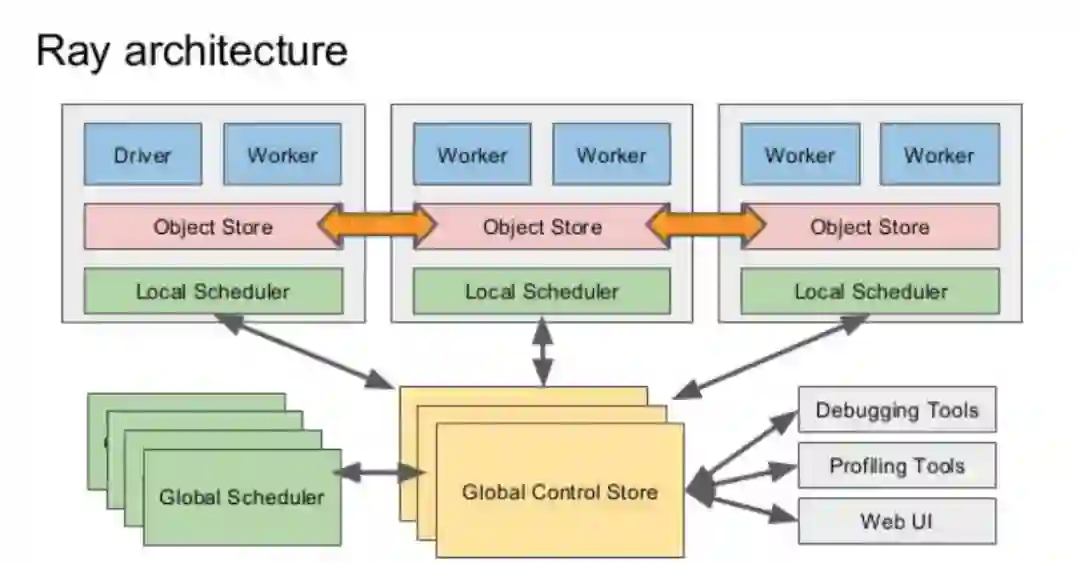
Ray can be used standalone by calling ray.init() within a script. When the call to ray.init()happens, all of the relevant processes are started. These include a raylet, an object store and manager, a Redis server, and a number of worker processes.
When the script exits, these processes will be killed.
Connecting to an existing Ray cluster
To connect to an existing Ray cluster, simply pass the argument address of the Redis server as the redis_address= keyword argument into ray.init. In this case, no new processes will be started when ray.init is called, and similarly the processes will continue running when the script exits. In this case, all processes except workers that correspond to actors are shared between different driver processes.
3. Ray Processes
When using Ray, several processes are involved.
Multiple worker processes execute tasks and store results in object stores. Each worker is a separate process.
One object store per node stores immutable objects in shared memory and allows workers to efficiently share objects on the same node with minimal copying and deserialization.
One raylet per node assigns tasks to workers on the same node.
A driver is the Python process that the user controls. For example, if the user is running a script or using a Python shell, then the driver is the Python process that runs the script or the shell. A driver is similar to a worker in that it can submit tasks to its raylet and get objects from the object store, but it is different in that the raylet will not assign tasks to the driver to be executed.
A Redis server maintains much of the system’s state. For example, it keeps track of which objects live on which machines and of the task specifications (but not data). It can also be queried directly for debugging purposes.
4. Remote functions (Tasks)
Defining a remote function
A central component of this system is the centralized control plane. This is implemented using one or more Redis servers. Redis is an in-memory key-value store.
We use the centralized control plane in two ways. First, as persistent store of the system’s control state. Second, as a message bus for communication between processes ( using Redis’s publish-subscribe functionality ).
Now, consider a remote function definition as below.

When the remote function is defined as above, the function is immediately pickled, assigned a unique ID, and stored in a Redis server.
Each worker process has a separate thread running in the background that listens for the addition of remote functions to the centralized control state. When a new remote function is added, the thread fetches the pickled remote function, unpickles it, and can then execute that function.
Calling a remote function
When a driver or worker invokes a remote function, a number of things happen.
First, a task object is created. The task object includes the following.
The ID of the function being called.
The IDs or values of the arguments to the function. Python primitives like integers or short strings will be pickled and included as part of the task object. Larger or more complex objects will be put into the object store with an internal call to
ray.put, and the resulting IDs are included in the task object. Object IDs that are passed directly as arguments are also included in the task object.The ID of the task. This is generated uniquely from the above content.
The IDs for the return values of the task. These are generated uniquely from the above content.
The task object is then sent to the raylet on the same node as the driver or worker.
The raylet makes a decision to either schedule the task locally or to pass the task on to another raylet.
If all of the task’s object dependencies are present in the local object store and there are enough CPU and GPU resources available to execute the task, then the raylet will assign the task to one of its available workers.
If those conditions are not met, the task will be forwarded to another raylet. This is done by peer-to-peer connection between raylets. The task table can be inspected as follows.
5. Ray Objects
Getting an object ID
Several things happen when a driver or worker calls ray.get on an object ID.
The driver or worker goes to the object store on the same node and requests the relevant object. Each object store consists of two components, a shared-memory key-value store of immutable objects, and a manager to coordinate the transfer of objects between nodes.
If the object is not present in the object store, the manager checks the object table to see which other object stores, if any, have the object. It then requests the object directly from one of those object stores, via its manager. If the object doesn’t exist anywhere, then the centralized control state will notify the requesting manager when the object is created. If the object doesn’t exist anywhere because it has been evicted from all object stores, the worker will also request reconstruction of the object from the raylet. These checks repeat periodically until the object is available in the local object store, whether through reconstruction or through object transfer.
Once the object is available in the local object store, the driver or worker will map the relevant region of memory into its own address space (to avoid copying the object), and will deserialize the bytes into a Python object. Note that any numpy arrays that are part of the object will not be copied.
6. Remote Classes (Actors)
Actors extend the Ray API from functions (tasks) to classes. The ray.remote decorator indicates that instances of the class will be actors. An actor is essentially a stateful worker. Each actor runs in its own Python process.
When an actor is instantiated, the following events happen.
A worker Python process is started on a node of the cluster.
A class object is instantiated on that worker.

参考资料:
https://ray.readthedocs.io/en/latest/walkthrough.html
https://ray.readthedocs.io/en/latest/internals-overview.html


