
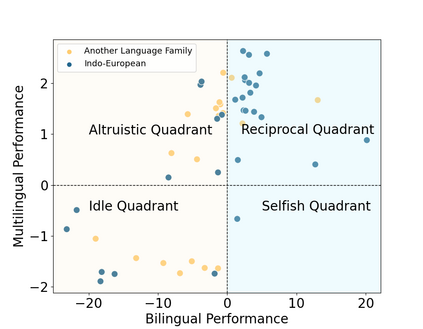
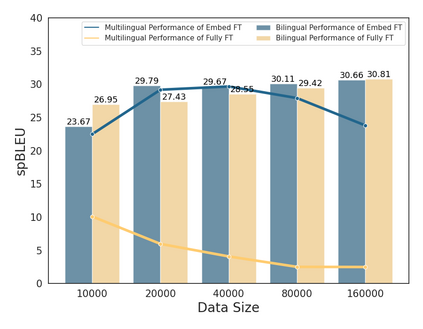
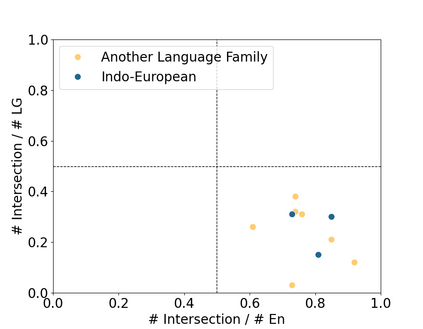
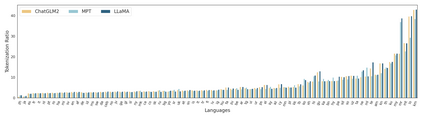
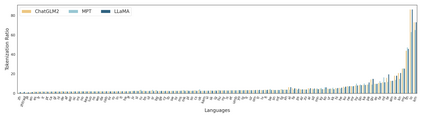
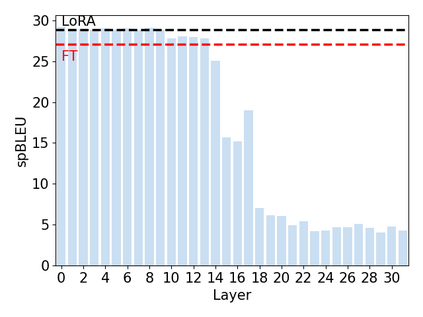
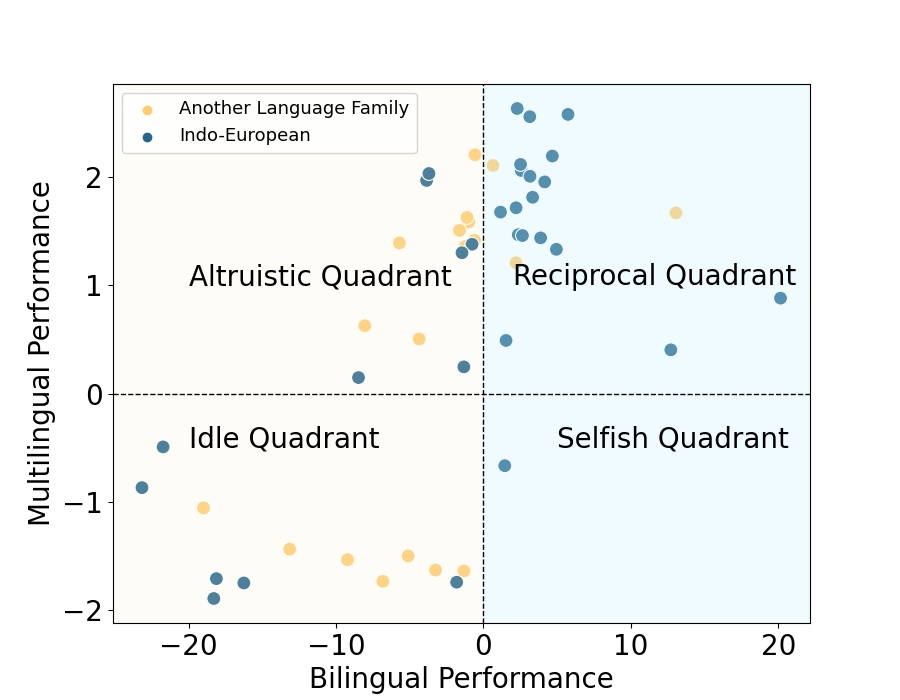
Large Language Models (LLMs), trained predominantly on extensive English data, often exhibit limitations when applied to other languages. Current research is primarily focused on enhancing the multilingual capabilities of these models by employing various tuning strategies. Despite their effectiveness in certain languages, the understanding of the multilingual abilities of LLMs remains incomplete. This study endeavors to evaluate the multilingual capacity of LLMs by conducting an exhaustive analysis across 101 languages, and classifies languages with similar characteristics into four distinct quadrants. By delving into each quadrant, we shed light on the rationale behind their categorization and offer actionable guidelines for tuning these languages. Extensive experiments reveal that existing LLMs possess multilingual capabilities that surpass our expectations, and we can significantly improve the multilingual performance of LLMs by focusing on these distinct attributes present in each quadrant.
翻译:暂无翻译
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

