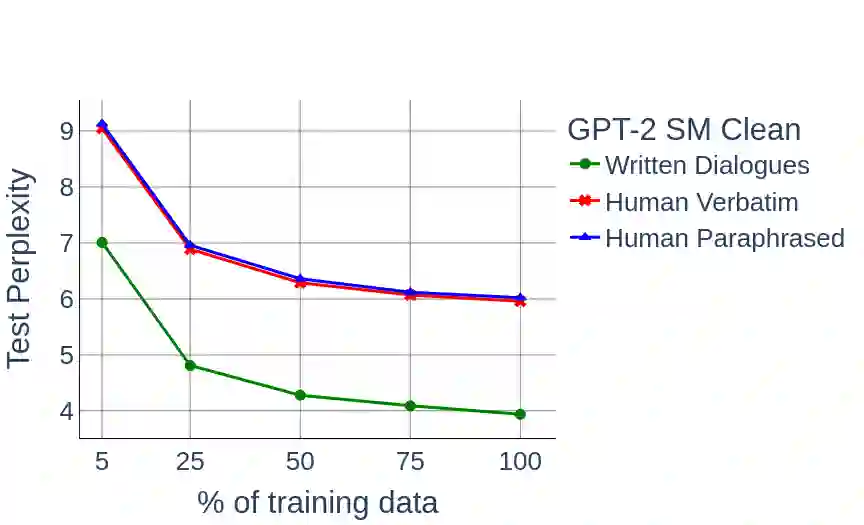
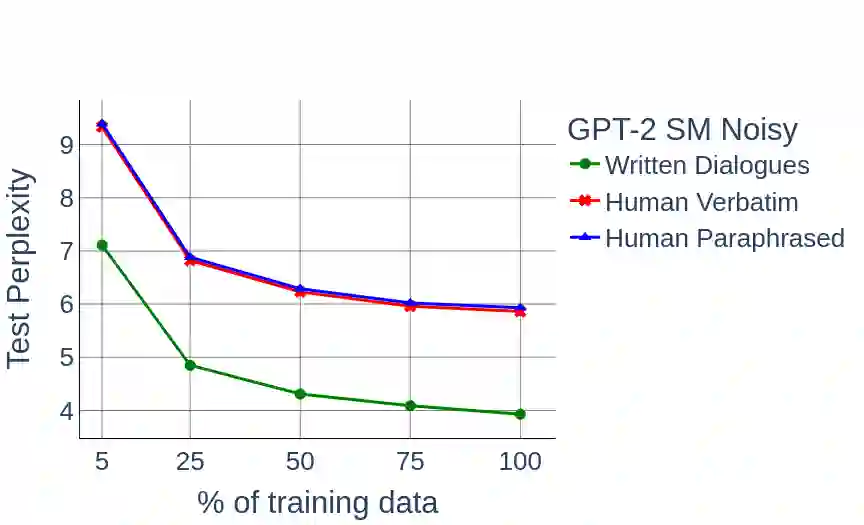
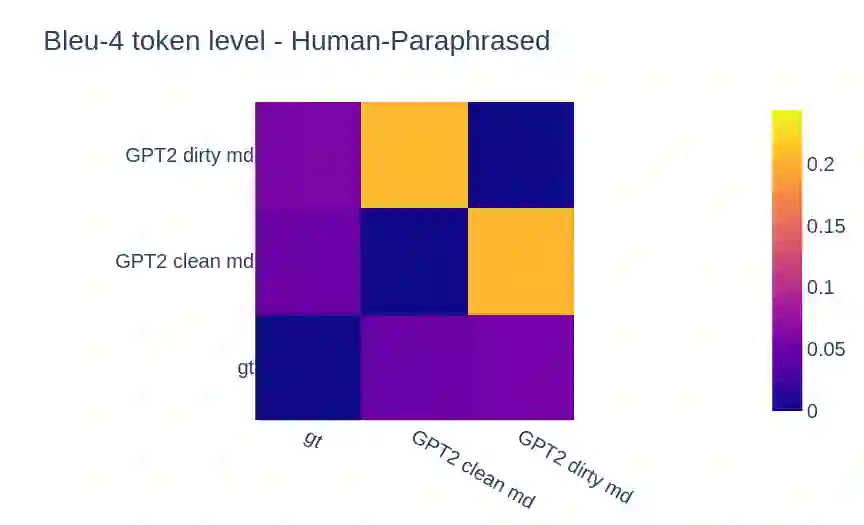
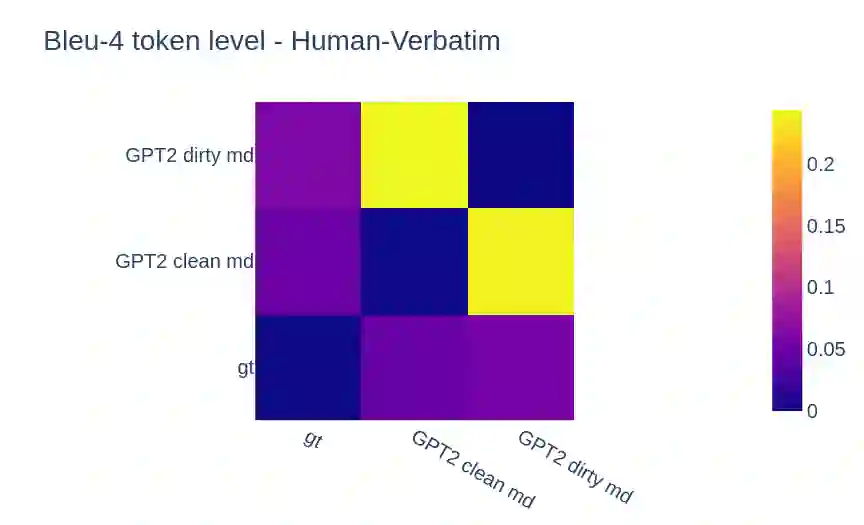
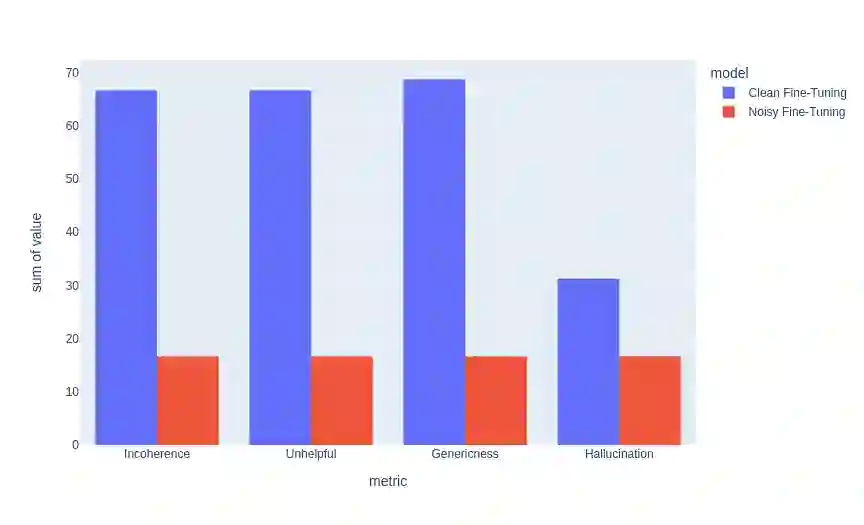
Large Pre-Trained Language Models have demonstrated state-of-the-art performance in different downstream tasks, including dialogue state tracking and end-to-end response generation. Nevertheless, most of the publicly available datasets and benchmarks on task-oriented dialogues focus on written conversations. Consequently, the robustness of the developed models to spoken interactions is unknown. In this work, we have evaluated the performance of LLMs for spoken task-oriented dialogues on the DSTC11 test sets. Due to the lack of proper spoken dialogue datasets, we have automatically transcribed a development set of spoken dialogues with a state-of-the-art ASR engine. We have characterized the ASR-error types and their distributions and simulated these errors in a large dataset of dialogues. We report the intrinsic (perplexity) and extrinsic (human evaluation) performance of fine-tuned GPT-2 and T5 models in two subtasks of response generation and dialogue state tracking, respectively. The results show that LLMs are not robust to spoken noise by default, however, fine-tuning/training such models on a proper dataset of spoken TODs can result in a more robust performance.
翻译:暂无翻译