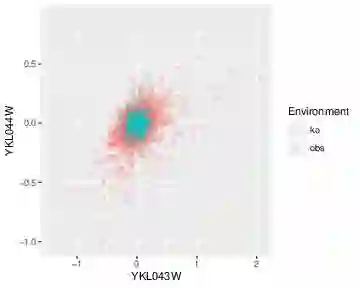
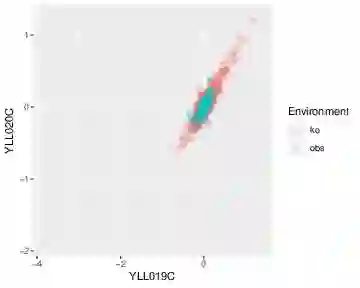
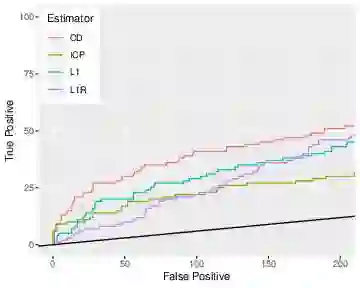
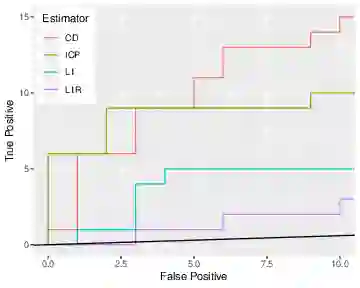
Causal models are notoriously difficult to validate because they make untestable assumptions regarding confounding. New scientific experiments offer the possibility of evaluating causal models using prediction performance. Prediction performance measures are typically robust to violations in causal assumptions. However prediction performance does depend on the selection of training and test sets. In particular biased training sets can lead to optimistic assessments of model performance. In this work, we revisit the prediction performance of several recently proposed causal models tested on a genetic perturbation data set of Kemmeren [Kemmeren et al., 2014]. We find that sample selection bias is likely a key driver of model performance. We propose using a less-biased evaluation set for assessing prediction performance on Kemmeren and compare models on this new set. In this setting, the causal model tested have similar performance to standard association based estimators such as Lasso. Finally we compare the performance of causal estimators in simulation studies which reproduce the Kemmeren structure of genetic knockout experiments but without any sample selection bias. These results provide an improved understanding of the performance of several causal models and offer guidance on how future studies should use Kemmeren.
翻译:众所周知,因果模型很难验证,因为它们对混亂作了无法检验的假设。新的科学实验提供了利用预测性能评估因果模型的可能性。预测性绩效措施通常对因果假设的违反情况十分有力。但预测性业绩则取决于培训和测试组的选择情况。特别有偏向的培训组可以对模型性能进行乐观的评估。在这项工作中,我们重新审视最近根据Kemmeren[Kemmeren等人,2014年]的基因扰动数据集测试的数个拟议因果模型的预测性能。我们发现,抽样选择偏差可能是模型性能的一个关键驱动因素。我们提议使用一个不太偏差的评价组来评估Kemmeren的预测性能并比较这一新组的模型。在这种环境中,所测试的因果模型的性能与Lasso等标准估计者相似。最后,我们比较了模拟研究中的一些因果估计员的性能,这些模拟研究复制了基因敲门实验的Kemmeren结构,但没有选择偏差。这些结果为若干因果模型的性能提供更好的了解,并指导未来研究如何使用Kemmeren。