
题目: Video Description: A Survey of Methods, Datasets, and Evaluation Metrics
简介: 视频描述是对给定视频内容自动生成描述语言。它在人机交互中具有应用程序,可帮助视障人士和视频字幕。过去几年中,由于深度学习在计算机视觉和自然语言处理方面取得了空前的成功,因此该领域的研究激增。文献中已经提出了许多方法,数据集和评估指标,这要求进行全面调查以将研究工作集中在这个蓬勃发展的新方向上。本文通过重点研究深度学习模型的最新方法来填补这一空白。比较基准数据集的域,类数和存储库大小;并确定各种评估指标(例如SPICE,CIDEr,ROUGE,BLEU,METEOR和WMD)的优缺点。经典的视频描述方法将主语,宾语和动词检测与基于模板的语言模型相结合,以生成句子。但是,大型数据集的发布表明,这些方法无法应对不受约束的开放域视频的多样性。古典方法之后是很短的统计方法时代,很快就被深度学习所取代,后者是视频描述中的最新技术。我们的调查显示,尽管发展迅速,但由于以下原因,视频描述研究仍处于起步阶段:视频描述模型的分析具有挑战性,因为难以确定对视觉特征的准确性或误差的贡献。最终描述中采用的语言模型。现有的数据集既不包含足够的视觉多样性,也不包含语言结构的复杂性。最后,当前的评价指标未能衡量机器生成的描述与人类描述之间的一致性。
成为VIP会员查看完整内容
相关内容

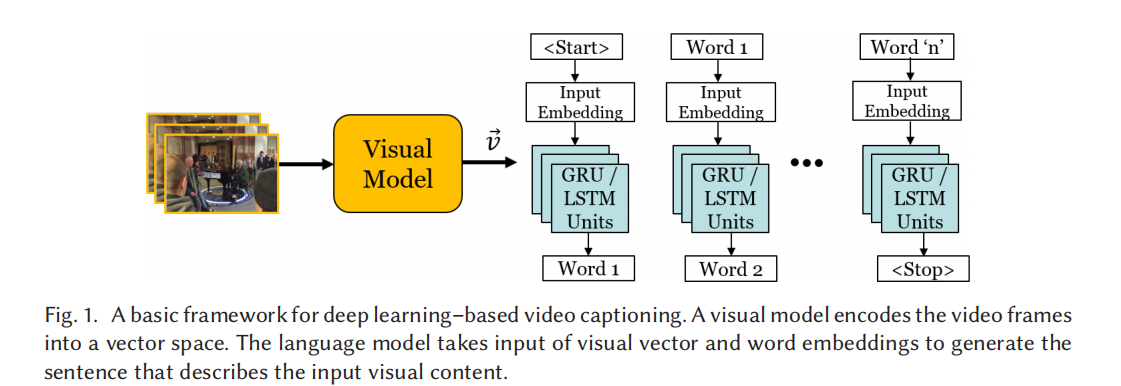
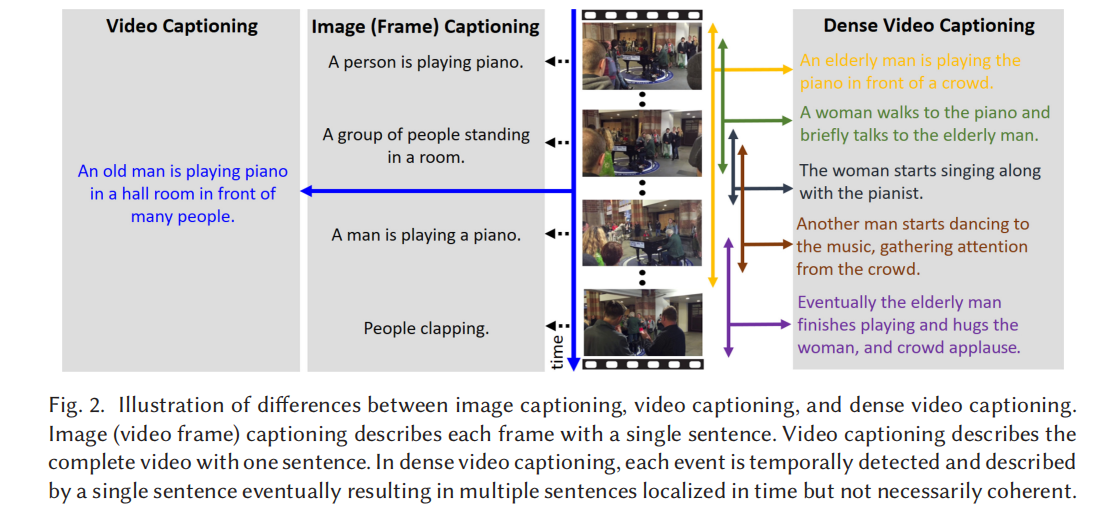
视频描述生成(Video Caption),就是从视频中自动生成一段描述性文字
专知会员服务
100+阅读 · 2019年11月23日
专知会员服务
85+阅读 · 2019年11月15日
Arxiv
4+阅读 · 2018年7月4日


相关VIP内容
专知会员服务
100+阅读 · 2019年11月23日
专知会员服务
85+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年7月4日