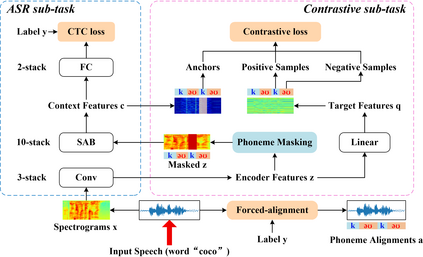
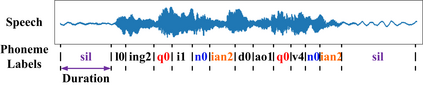
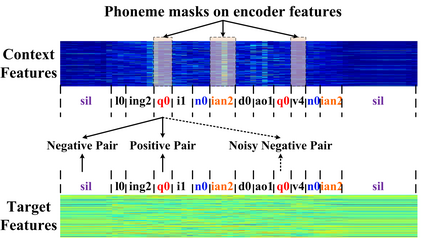
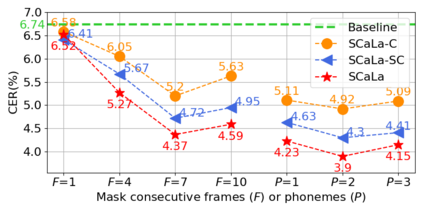
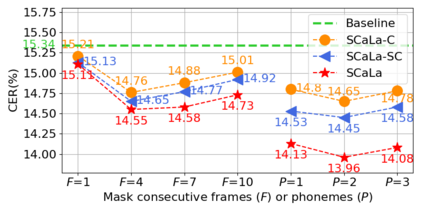
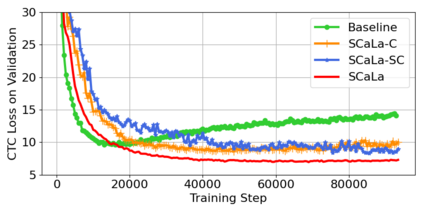
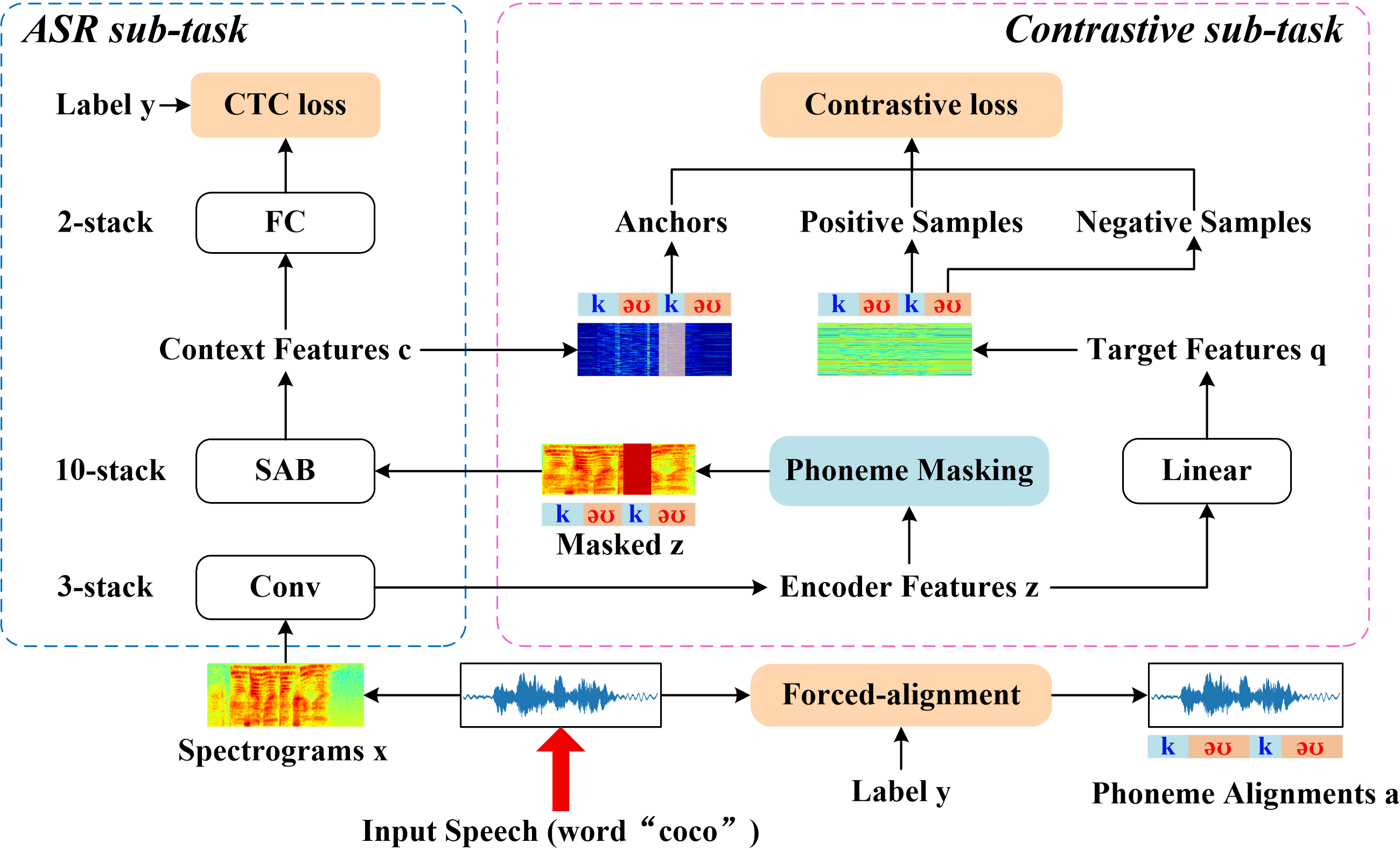
End-to-end Automatic Speech Recognition (ASR) models are usually trained to reduce the losses of the whole token sequences, while neglecting explicit phonemic-granularity supervision. This could lead to recognition errors due to similar-phoneme confusion or phoneme reduction. To alleviate this problem, this paper proposes a novel framework of Supervised Contrastive Learning (SCaLa) to enhance phonemic information learning for end-to-end ASR systems. Specifically, we introduce the self-supervised Masked Contrastive Predictive Coding (MCPC) into the fully-supervised setting. To supervise phoneme learning explicitly, SCaLa first masks the variable-length encoder features corresponding to phonemes given phoneme forced-alignment extracted from a pre-trained acoustic model, and then predicts the masked phonemes via contrastive learning. The phoneme forced-alignment can mitigate the noise of positive-negative pairs in self-supervised MCPC. Experimental results conducted on reading and spontaneous speech datasets show that the proposed approach achieves 2.84% and 1.38% Character Error Rate (CER) reductions compared to the baseline, respectively.
翻译:终端到终端自动语音识别模型通常经过培训,以减少整个象征性序列的损失,同时忽视显眼语音-突扰监督。 这可能会导致类似手机混乱或减少电话机的减少导致识别错误。 为了缓解这一问题,本文件提议了一个新型的 " 监督对终端自动语音识别(SCala) " 框架, 以加强终端到终端自动语音识别系统的语音信息学习。 具体地说, 我们引入了自监管的全监控设置, 并同时忽略了显眼式语音识别( MCPC ) 。 为了明确监督电话学习, SCaLa 首次掩盖了从预先培训的音学模型中提取的与电话磁带强制对接对应的可变长编码功能, 然后通过对比性学习预测遮蔽式电话。 电话强制调节可以减轻自监管的 MCPC 中正面负式对子的噪音。 在阅读和自发语音数据集中进行的实验结果显示, 与基线相比, 拟议的方法分别达到2.84%和1.38 % 的字符错误率(CER) 。