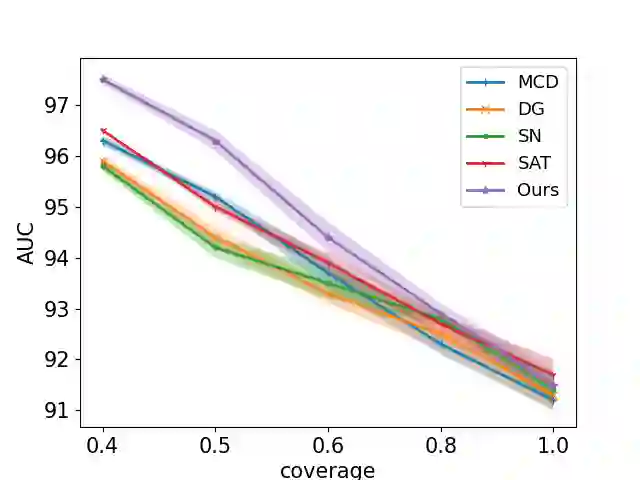
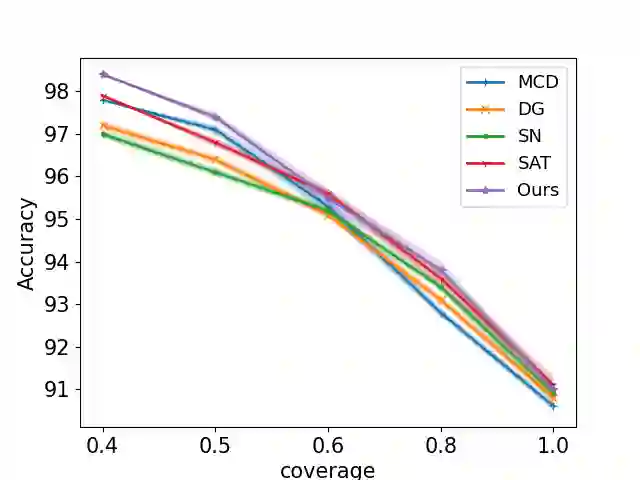
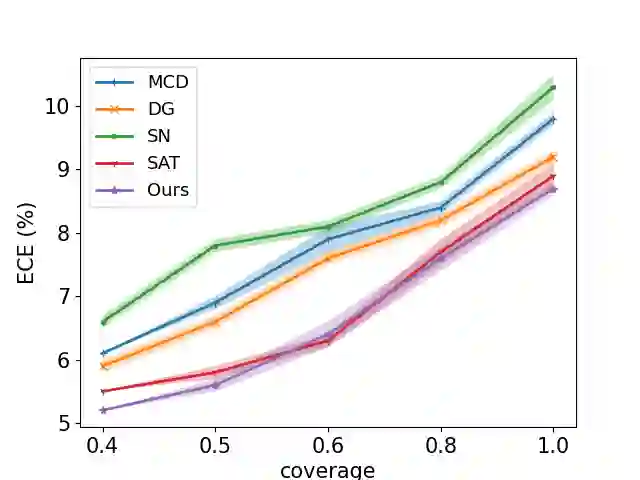
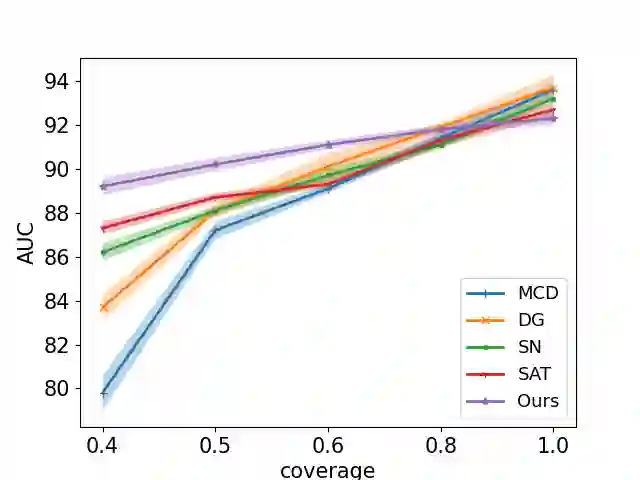
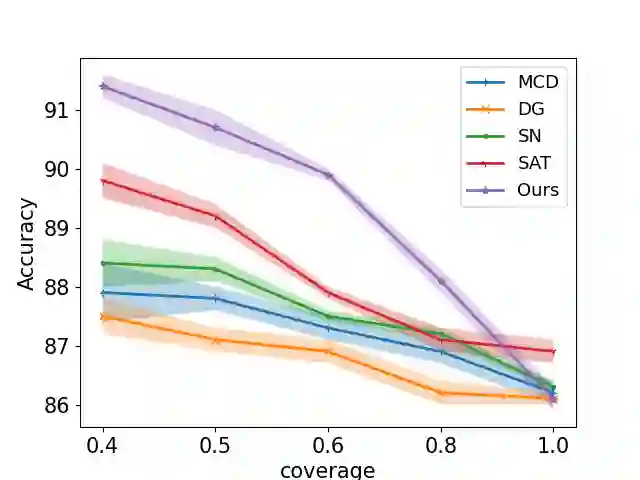
Selective classification involves identifying the subset of test samples that a model can classify with high accuracy, and is important for applications such as automated medical diagnosis. We argue that this capability of identifying uncertain samples is valuable for training classifiers as well, with the aim of building more accurate classifiers. We unify these dual roles by training a single auxiliary meta-network to output an importance weight as a function of the instance. This measure is used at train time to reweight training data, and at test-time to rank test instances for selective classification. A second, key component of our proposal is the meta-objective of minimizing dropout variance (the variance of classifier output when subjected to random weight dropout) for training the metanetwork. We train the classifier together with its metanetwork using a nested objective of minimizing classifier loss on training data and meta-loss on a separate meta-training dataset. We outperform current state-of-the-art on selective classification by substantial margins--for instance, upto 1.9% AUC and 2% accuracy on a real-world diabetic retinopathy dataset. Finally, our meta-learning framework extends naturally to unsupervised domain adaptation, given our unsupervised variance minimization meta-objective. We show cumulative absolute gains of 3.4% / 3.3% accuracy and AUC over the other baselines in domain shift settings on the Retinopathy dataset using unsupervised domain adaptation.
翻译:选择性分类涉及确定一个模型可以高精度分类的测试样本的子集,对于自动化医疗诊断等应用非常重要。我们争辩说,这种识别不确定样本的能力对于培训分类员也十分宝贵,目的是建立更准确的分类器。我们通过培训单一辅助元网络,将这些双重作用统一起来,以输出一个重要重量作为实例的函数。这项措施在火车时间用于重量培训数据,在测试时间用于评定选择性分类的测试实例。第二,我们提案的关键组成部分是最大限度地减少辍学差异的元目标(分类器输出在随机减重时的差异),用于培训元网络。我们利用嵌套式目标,即最大限度地减少分类者在培训数据方面的损失和在单独元培训数据集中的元损失,对分类者进行培训。我们比目前关于选择性分类的状态(例如,通过边距来重新加权培训数据)的状态要强得多,最高到1.9% ACUC和现实世界的糖尿病病变率数据设置的精确度为2%。最后,我们的元学习框架将与其元网络一起培训,同时采用嵌式目标,在培训数据上尽量减少分类损失和元数据损失。