
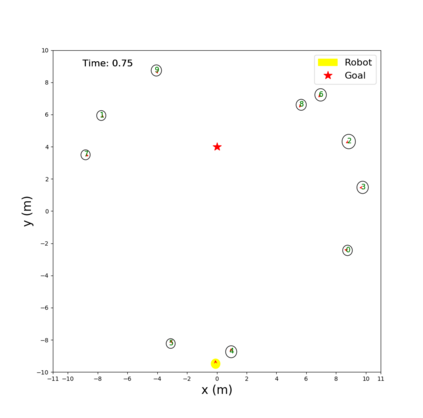
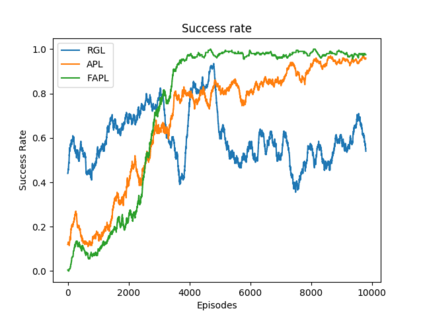
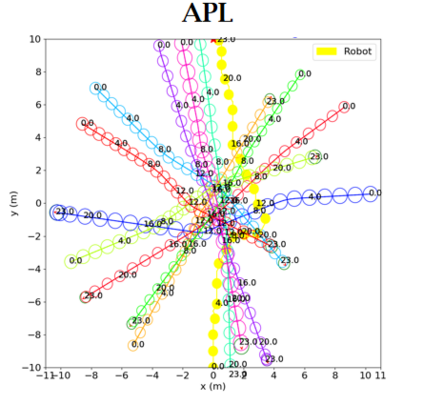
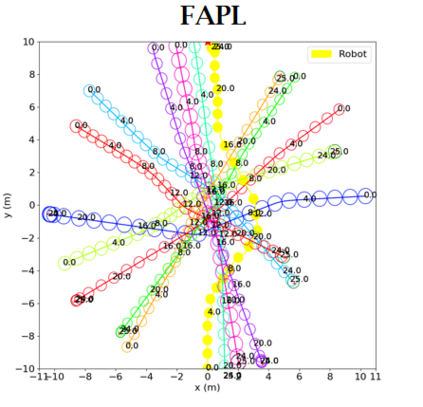
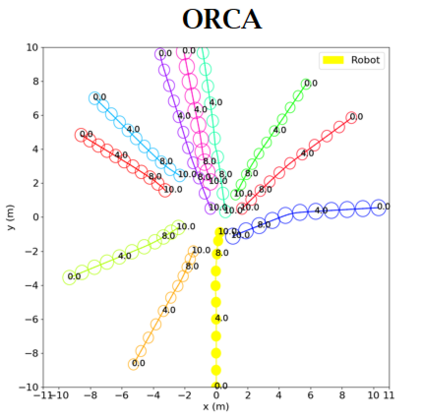
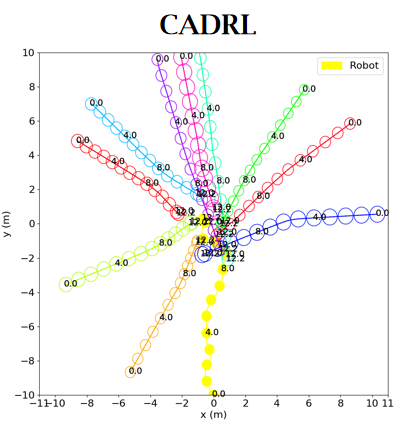
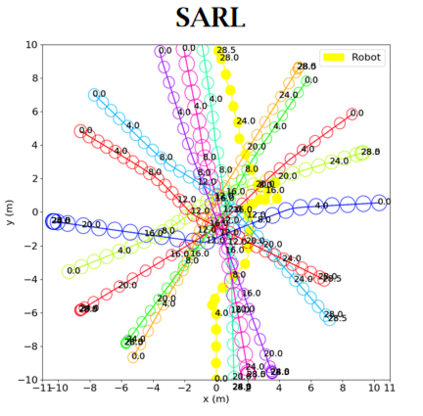
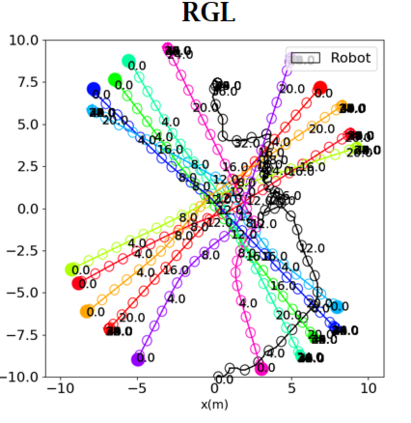
Socially aware robot navigation, where a robot is required to optimize its trajectories to maintain a comfortable and compliant spatial interaction with humans in addition to the objective of reaching the goal without collisions, is a fundamental yet challenging task for robots navigating in the context of human-robot interaction. Much as existing learning-based methods have achieved a better performance than previous model-based ones, they still have some drawbacks: the reinforcement learning approaches, which reply on a handcrafted reward for optimization, are unlikely to emulate social compliance comprehensively and can lead to reward exploitation problems; the inverse reinforcement learning approaches, which learn a policy via human demonstrations, suffer from expensive and partial samples, and need extensive feature engineering to be reasonable. In this paper, we propose FAPL, a feedback-efficient interactive reinforcement learning approach that distills human preference and comfort into a reward model, which serves as a teacher to guide the agent to explore latent aspects of social compliance. Hybrid experience and off-policy learning are introduced to improve the efficiency of samples and human feedback. Extensive simulation experiments demonstrate the advantages of FAPL quantitatively and qualitatively.
翻译:在有社会意识的机器人导航方面,机器人需要优化其轨道,以保持与人类之间的舒适和兼容的空间互动,除了实现不发生碰撞的目标之外,还必须保持与人类之间的舒适和兼容的空间互动,这是在人类-机器人互动的背景下航行的机器人的一项根本性但具有挑战性的任务。现有基于学习的方法取得了比以往基于模型的方法更好的性能,但是它们仍然有一些缺点:在优化的手工奖励上做出回应的强化学习方法不可能全面仿效社会合规,并可能导致奖励剥削问题;反强化学习方法,通过人类演示学习一项政策,遭受昂贵和局部的样本,需要广泛的特征工程才能合理;在本文件中,我们建议采用反馈高效的互动强化学习方法,将人类的喜好和安慰转化为奖励模式,作为指导代理人探索社会合规的潜在方面的教师;引入混合经验和非政策学习,以提高样本和人类反馈的效率;广泛模拟实验显示了FAPL的定量和定性优势。









相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem



