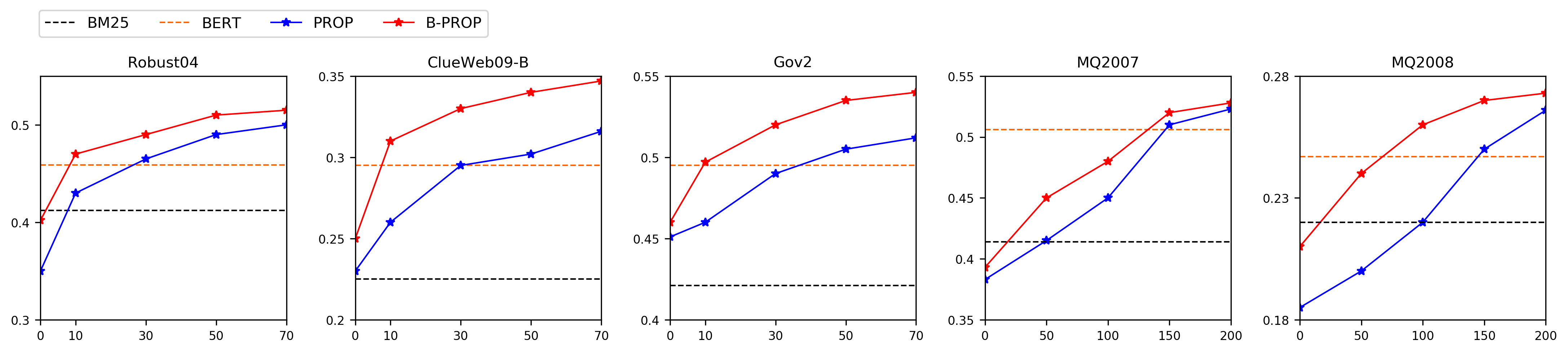
Pre-training and fine-tuning have achieved remarkable success in many downstream natural language processing (NLP) tasks. Recently, pre-training methods tailored for information retrieval (IR) have also been explored, and the latest success is the PROP method which has reached new SOTA on a variety of ad-hoc retrieval benchmarks. The basic idea of PROP is to construct the \textit{representative words prediction} (ROP) task for pre-training inspired by the query likelihood model. Despite its exciting performance, the effectiveness of PROP might be bounded by the classical unigram language model adopted in the ROP task construction process. To tackle this problem, we propose a bootstrapped pre-training method (namely B-PROP) based on BERT for ad-hoc retrieval. The key idea is to use the powerful contextual language model BERT to replace the classical unigram language model for the ROP task construction, and re-train BERT itself towards the tailored objective for IR. Specifically, we introduce a novel contrastive method, inspired by the divergence-from-randomness idea, to leverage BERT's self-attention mechanism to sample representative words from the document. By further fine-tuning on downstream ad-hoc retrieval tasks, our method achieves significant improvements over baselines without pre-training or with other pre-training methods, and further pushes forward the SOTA on a variety of ad-hoc retrieval tasks.
翻译:培训前和微调在许多下游自然语言处理(NLP)任务中取得了显著成功。最近,还探索了专门为信息检索(IR)设计的训练前前方法,最近的成功是PROP方法,该方法在各种特别检索基准的基础上达到了新的SOTA。PROP的基本想法是,根据查询可能性模型,为培训前设计“Textit{代表词预测}”(ROP)任务。尽管其业绩令人振奋,但PROP的效力可能受到在ROP任务建设过程中采用的传统单一语言模式的束缚。为了解决这一问题,我们提议采用基于BERT的培训前方法(即B-PROP),以新的SUP方法(即B-PROP)为基础,为临时检索制定新的SOTA方法。关键的想法是,利用强大的背景语言模型BERT,以取代为ROP任务构建的经典的ungram语言模式,并重新培训BERT本身,以实现为IR的目标。具体地说,我们采用了一种新型的对比方法,其灵感是差异性调整概念,在BERT的升级后,在不需进一步调整文件前的升级方法上采用重大的SERT的升级方法,在前的升级方法上实现。