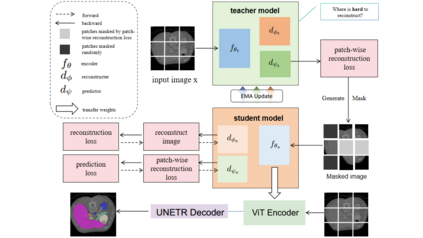
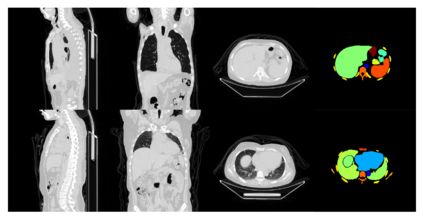
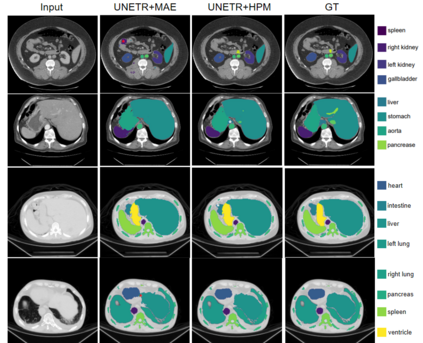
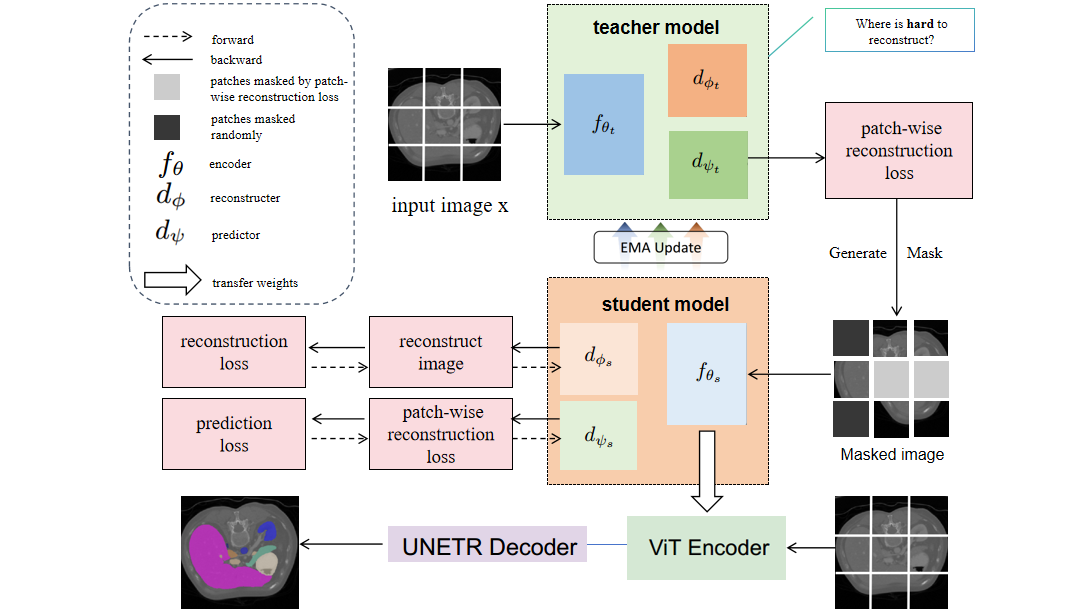
In recent years, deep learning methods such as convolutional neural network (CNN) and transformers have made significant progress in CT multi-organ segmentation. However, CT multi-organ segmentation methods based on masked image modeling (MIM) are very limited. There are already methods using MAE for CT multi-organ segmentation task, we believe that the existing methods do not identify the most difficult areas to reconstruct. To this end, we propose a MIM self-training framework with hard patches mining masked autoencoders for CT multi-organ segmentation tasks (selfMedHPM). The method performs ViT self-pretraining on the training set of the target data and introduces an auxiliary loss predictor, which first predicts the patch loss and determines the location of the next mask. SelfMedHPM implementation is better than various competitive methods in abdominal CT multi-organ segmentation and body CT multi-organ segmentation. We have validated the performance of our method on the Multi Atlas Labeling Beyond The Cranial Vault (BTCV) dataset for abdomen mult-organ segmentation and the SinoMed Whole Body (SMWB) dataset for body multi-organ segmentation tasks.
翻译:暂无翻译