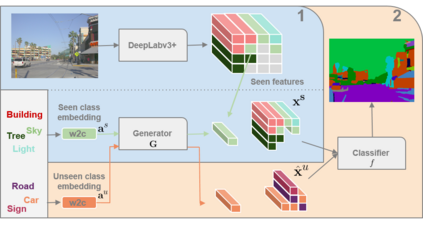
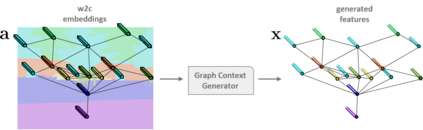
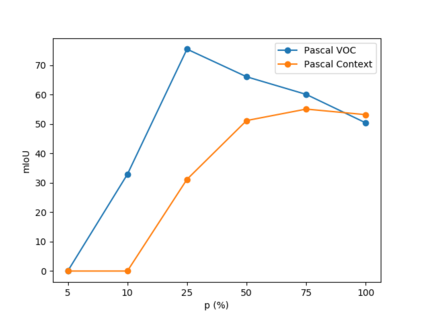
Semantic segmentation models are limited in their ability to scale to large numbers of object classes. In this paper, we introduce the new task of zero-shot semantic segmentation: learning pixel-wise classifiers for never-seen object categories with zero training examples. To this end, we present a novel architecture, ZS3Net, combining a deep visual segmentation model with an approach to generate visual representations from semantic word embeddings. By this way, ZS3Net addresses pixel classification tasks where both seen and unseen categories are faced at test time (so called "generalized" zero-shot classification). Performance is further improved by a self-training step that relies on automatic pseudo-labeling of pixels from unseen classes. On the two standard segmentation datasets, Pascal-VOC and Pascal-Context, we propose zero-shot benchmarks and set competitive baselines. For complex scenes as ones in the Pascal-Context dataset, we extend our approach by using a graph-context encoding to fully leverage spatial context priors coming from class-wise segmentation maps.
翻译:语义分解模型在向大量对象分类进行缩放的能力方面受到限制。 在本文中, 我们引入了零光语义分解的新任务 : 学习不见目标类别的像素分解器, 并进行零培训。 为此, 我们提出了一个新颖的结构, ZS3Net, 将深视分解模型与从语义嵌入中生成视觉表达的方法结合起来。 这样, ZS3Net 处理在测试时既面临可见类别又面临不可见类别的像素分类( 所谓的“ 通用” 零分解 分类 ) 。 通过自我培训步骤, 依靠对不可见类分解的像素自动作假标签来进一步改进性能。 在两个标准分解数据集, Pascal- VoC 和 Pascal- Context 上, 我们提出了零光基准和设定竞争性基线。 在Pascal- Context 数据集的复杂场景中, 我们扩展了我们的方法, 使用图形- 格式编码来充分利用来自类分解图解图地图上的空间环境 。