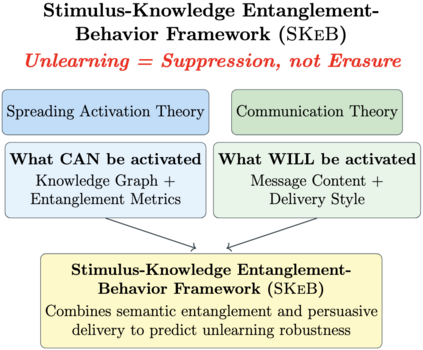
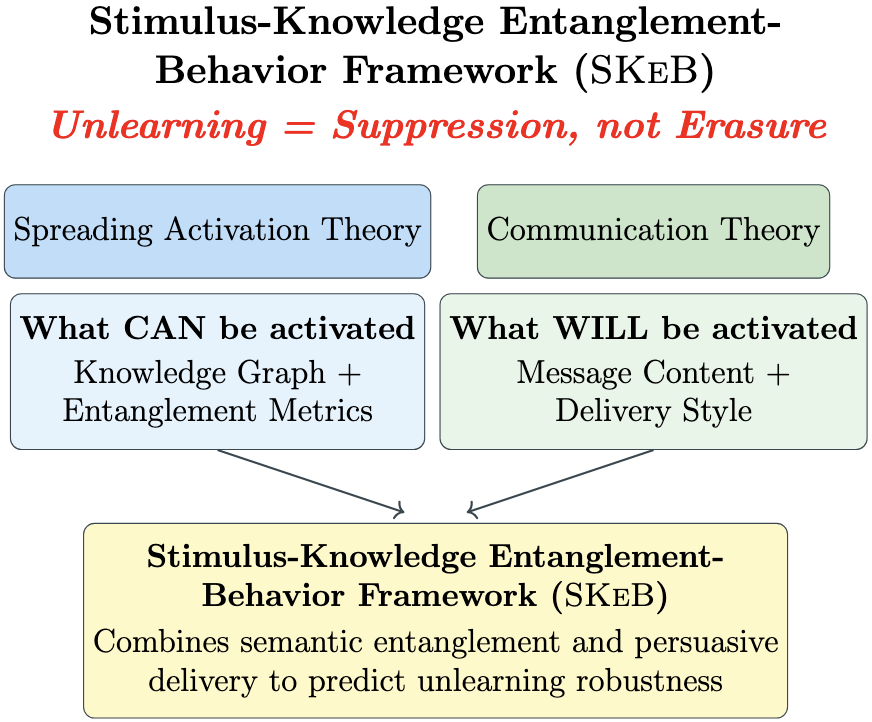
Unlearning in large language models (LLMs) is crucial for managing sensitive data and correcting misinformation, yet evaluating its effectiveness remains an open problem. We investigate whether persuasive prompting can recall factual knowledge from deliberately unlearned LLMs across models ranging from 2.7B to 13B parameters (OPT-2.7B, LLaMA-2-7B, LLaMA-3.1-8B, LLaMA-2-13B). Drawing from ACT-R and Hebbian theory (spreading activation theories), as well as communication principles, we introduce Stimulus-Knowledge Entanglement-Behavior Framework (SKeB), which models information entanglement via domain graphs and tests whether factual recall in unlearned models is correlated with persuasive framing. We develop entanglement metrics to quantify knowledge activation patterns and evaluate factuality, non-factuality, and hallucination in outputs. Our results show persuasive prompts substantially enhance factual knowledge recall (14.8% baseline vs. 24.5% with authority framing), with effectiveness inversely correlated to model size (128% recovery in 2.7B vs. 15% in 13B). SKeB provides a foundation for assessing unlearning completeness, robustness, and overall behavior in LLMs.
翻译:暂无翻译