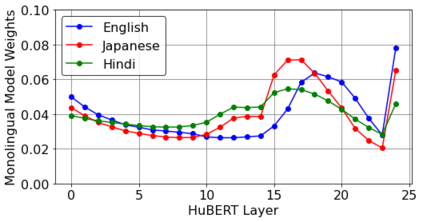
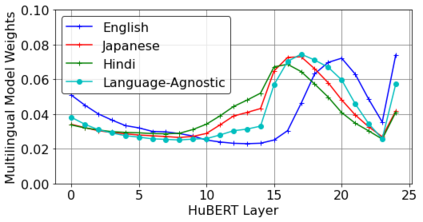
This work investigates the use of large-scale, pre-trained models (CLIP and HuBERT) for multilingual speech-image retrieval. For non-English speech-image retrieval, we outperform the current state-of-the-art performance by a wide margin when training separate models for each language, and show that a single model which processes speech in all three languages still achieves retrieval scores comparable with the prior state-of-the-art. We identify key differences in model behavior and performance between English and non-English settings, presumably attributable to the English-only pre-training of CLIP and HuBERT. Finally, we show that our models can be used for mono- and cross-lingual speech-text retrieval and cross-lingual speech-speech retrieval, despite never having seen any parallel speech-text or speech-speech data during training.
翻译:这项工作调查了在多语种语音图像检索方面使用大规模、预先培训的模型(CLIP和HuBERT)的情况。对于非英语语音图像检索来说,在为每种语言培训不同的模型时,我们表现的比目前最先进的成绩要大得多,并显示处理所有三种语言语言语言的单一模型仍然能取得与以前最先进的相比的检索分数。我们发现英语和非英语环境在示范行为和表现方面的主要差异,可能归因于CLIP和HuBERT仅以英语进行预先培训。最后,我们表明,我们的模型可以用于单语和跨语种语言语音检索和跨语言语音检索,尽管在培训期间从未看到过任何平行的语音文本或语音语音数据。