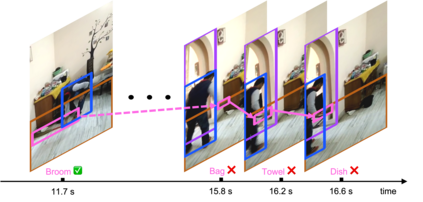
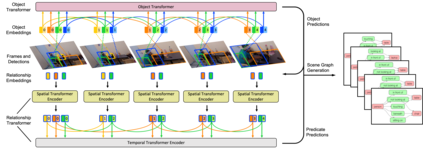
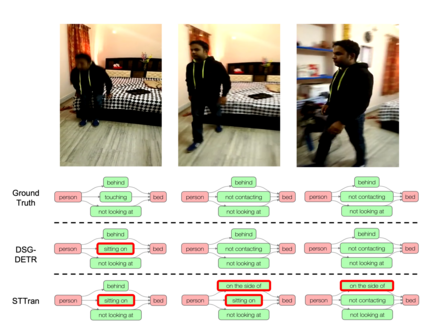
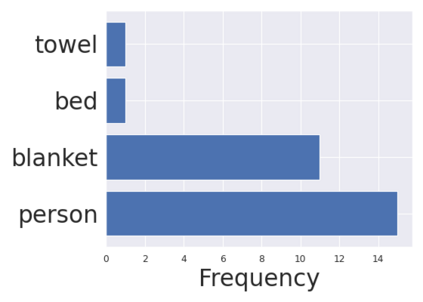
Dynamic scene graph generation from a video is challenging due to the temporal dynamics of the scene and the inherent temporal fluctuations of predictions. We hypothesize that capturing long-term temporal dependencies is the key to effective generation of dynamic scene graphs. We propose to learn the long-term dependencies in a video by capturing the object-level consistency and inter-object relationship dynamics over object-level long-term tracklets using transformers. Experimental results demonstrate that our Dynamic Scene Graph Detection Transformer (DSG-DETR) outperforms state-of-the-art methods by a significant margin on the benchmark dataset Action Genome. Our ablation studies validate the effectiveness of each component of the proposed approach. The source code is available at https://github.com/Shengyu-Feng/DSG-DETR.
翻译:由于场景的时间动态和预测固有的时间波动,从视频中生成动态场景图具有挑战性。我们假设,捕捉长期时间依赖性是有效生成动态场景图的关键。我们提议在视频中了解长期依赖性,方法是利用变压器捕捉物体级长期轨迹的物体级一致性和物体间关系动态。实验结果显示,我们的动态景色图探测变异器(DSG-DETR)在基准数据集行动基因组上有很大的比值,从而优于最新方法。我们的膨胀研究验证了拟议方法的每个组成部分的有效性。源代码见https://github.com/shengyu-Feng/DSG-DETR。