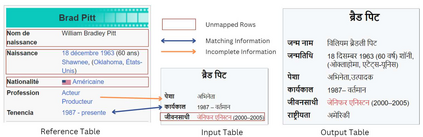
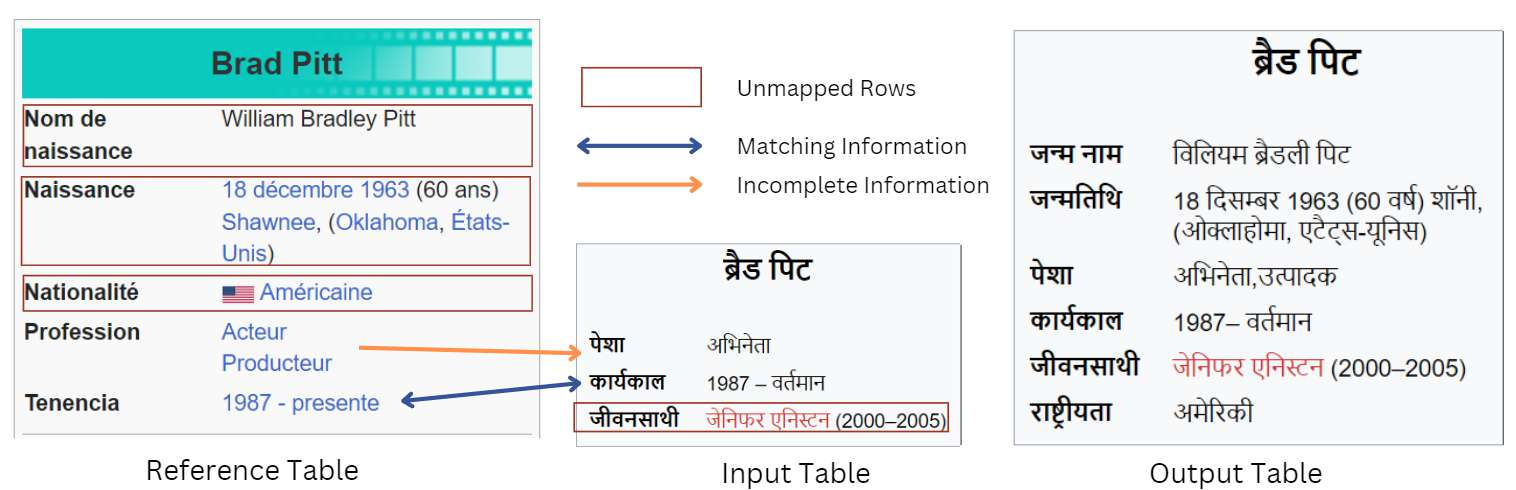
The vast amount of online information today poses challenges for non-English speakers, as much of it is concentrated in high-resource languages such as English and French. Wikipedia reflects this imbalance, with content in low-resource languages frequently outdated or incomplete. Recent research has sought to improve cross-language synchronization of Wikipedia tables using rule-based methods. These approaches can be effective, but they struggle with complexity and generalization. This paper explores large language models (LLMs) for multilingual information synchronization, using zero-shot prompting as a scalable solution. We introduce the Information Updation dataset, simulating the real-world process of updating outdated Wikipedia tables, and evaluate LLM performance. Our findings reveal that single-prompt approaches often produce suboptimal results, prompting us to introduce a task decomposition strategy that enhances coherence and accuracy. Our proposed method outperforms existing baselines, particularly in Information Updation (1.79%) and Information Addition (20.58%), highlighting the model strength in dynamically updating and enriching data across architectures
翻译:暂无翻译