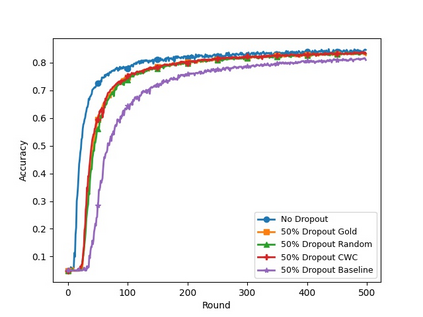
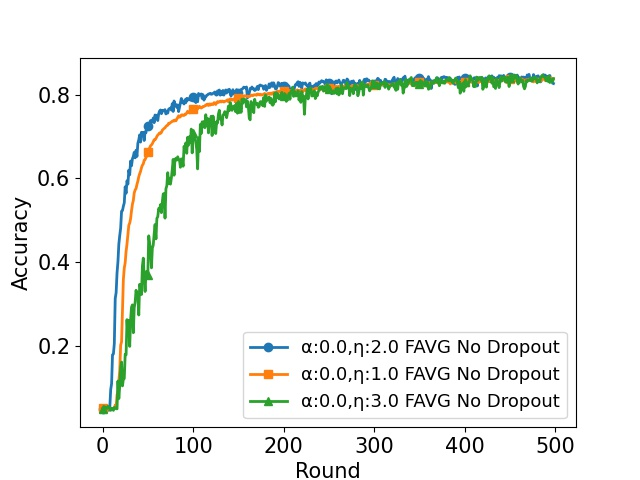
In cross-device Federated Learning (FL), clients with low computational power train a common\linebreak[4] machine model by exchanging parameters via updates instead of potentially private data. Federated Dropout (FD) is a technique that improves the communication efficiency of a FL session by selecting a \emph{subset} of model parameters to be updated in each training round. However, compared to standard FL, FD produces considerably lower accuracy and faces a longer convergence time. In this paper, we leverage \textit{coding theory} to enhance FD by allowing different sub-models to be used at each client. We also show that by carefully tuning the server learning rate hyper-parameter, we can achieve higher training speed while also achieving up to the same final accuracy as the no dropout case. For the EMNIST dataset, our mechanism achieves 99.6\% of the final accuracy of the no dropout case while requiring $2.43\times$ less bandwidth to achieve this level of accuracy.
翻译:在跨联邦学习(FL)中,计算功率低的客户通过更新而不是潜在的私人数据来交换参数,用通用的线性分解[4]机器模型,通过交换参数,用普通的分解[4]机器模型,而不是以潜在的私人数据。联邦辍学(FD)是一种技术,通过在每轮培训中选择一个模型参数的 emph{subset 来提高FL 会议的通信效率。然而,与标准的FL相比,FD 的准确性要低得多,并面临较长的趋同时间。在本文中,我们利用\ textit{coding理论},允许每个客户使用不同的子模型来增强FD。我们还表明,通过仔细调整服务器学习率的超参数,我们可以提高培训速度,同时达到与无辍学案例相同的最终精确度。对于EMNIST数据集来说,我们的机制实现了无辍学案例的最终准确度99.6 ⁇,同时要求减少带宽度为243美元。