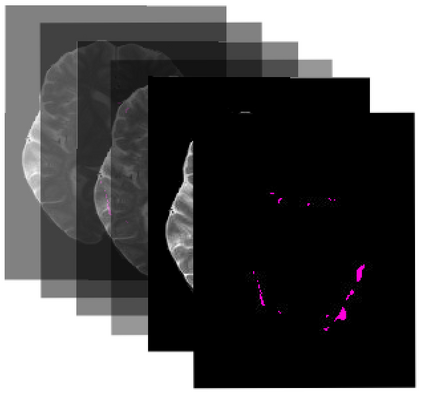
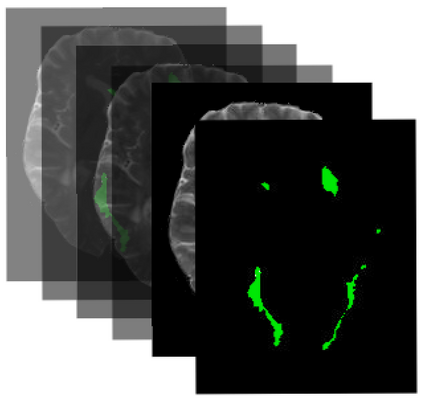
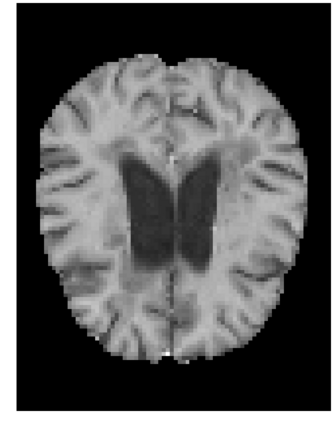
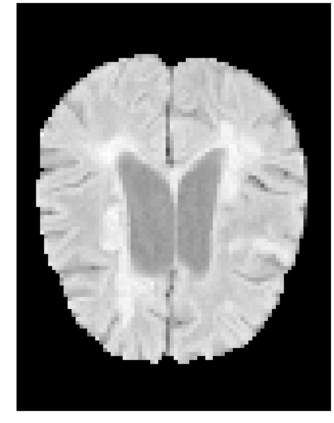
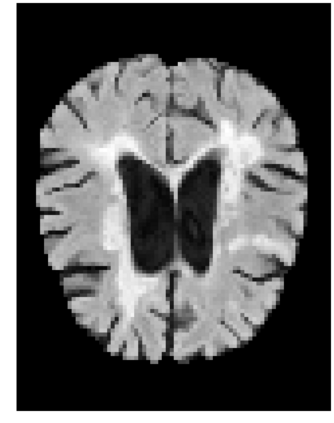
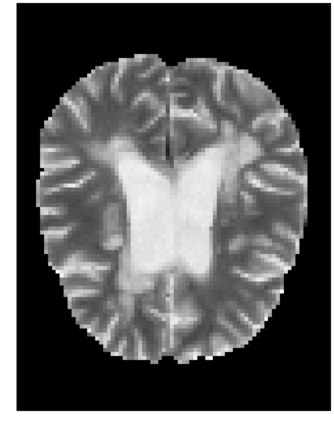
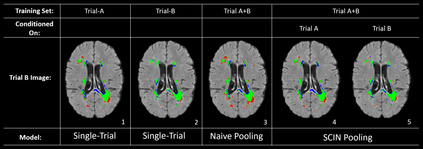
Many automatic machine learning models developed for focal pathology (e.g. lesions, tumours) detection and segmentation perform well, but do not generalize as well to new patient cohorts, impeding their widespread adoption into real clinical contexts. One strategy to create a more diverse, generalizable training set is to naively pool datasets from different cohorts. Surprisingly, training on this \it{big data} does not necessarily increase, and may even reduce, overall performance and model generalizability, due to the existence of cohort biases that affect label distributions. In this paper, we propose a generalized affine conditioning framework to learn and account for cohort biases across multi-source datasets, which we call Source-Conditioned Instance Normalization (SCIN). Through extensive experimentation on three different, large scale, multi-scanner, multi-centre Multiple Sclerosis (MS) clinical trial MRI datasets, we show that our cohort bias adaptation method (1) improves performance of the network on pooled datasets relative to naively pooling datasets and (2) can quickly adapt to a new cohort by fine-tuning the instance normalization parameters, thus learning the new cohort bias with only 10 labelled samples.
翻译:为焦点病理学(如损伤、肿瘤)检测和分解而开发的许多自动机器学习模型效果良好,但并不普遍适用于新的病人组群,妨碍他们被广泛采用到真正的临床环境中。创建更多样化、更普遍的培训组的战略是天性地汇集不同组群的数据集。奇怪的是,关于这一类组群的训练不一定增加,甚至可能降低整体性能和模型一般性,因为存在影响标签分布的群群群偏见。在本文件中,我们提议了一个通用的缝合框架,以学习和核算多源数据集组群偏向,我们称之为源-受限制的正常化(SCIN ) 。 通过对三种不同规模、大型、多扫描器、多中心多重分解(MS)临床试验 MRI 数据集进行广泛的实验,我们表明我们的群群偏差适应方法(1) 改善了与天真的集数据集相对的集合数据集网络性能,(2) 通过微调的定置像机群,只能通过精确的定型模型来迅速适应新的组群群。