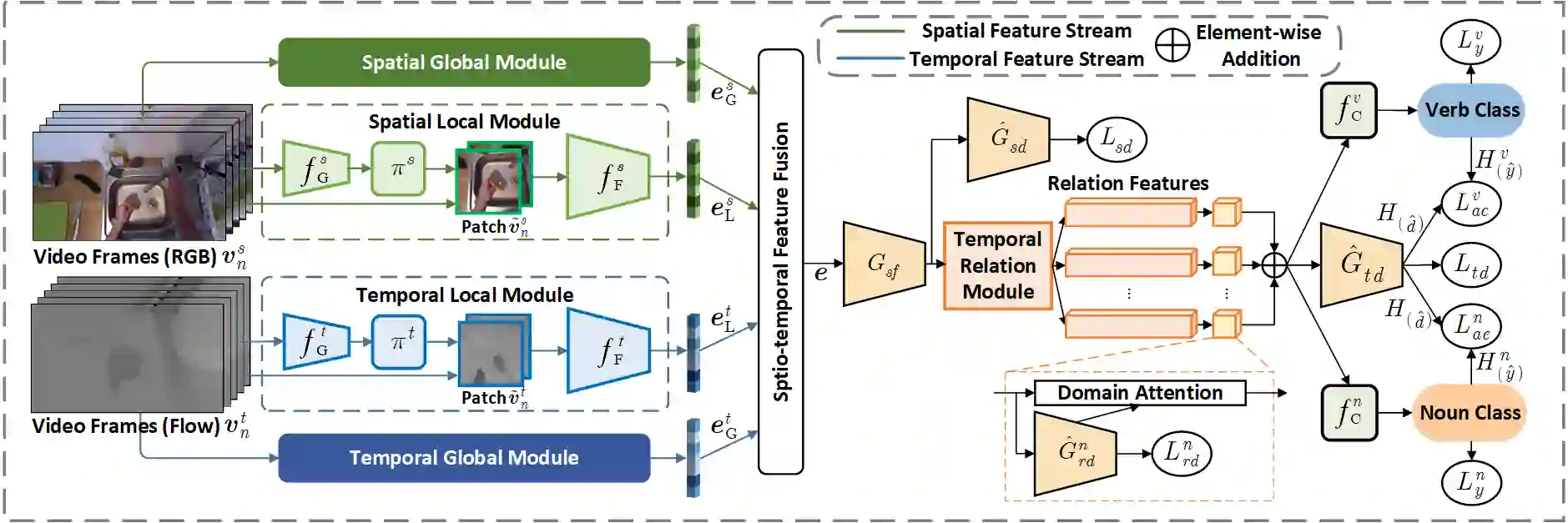
In this report, we present the technical details of our submission to the 2022 EPIC-Kitchens Unsupervised Domain Adaptation (UDA) Challenge. Existing UDA methods align the global features extracted from the whole video clips across the source and target domains but suffer from the spatial redundancy of feature matching in video recognition. Motivated by the observation that in most cases a small image region in each video frame can be informative enough for the action recognition task, we propose to exploit informative image regions to perform efficient domain alignment. Specifically, we first use lightweight CNNs to extract the global information of the input two-stream video frames and select the informative image patches by a differentiable interpolation-based selection strategy. Then the global information from videos frames and local information from image patches are processed by an existing video adaptation method, i.e., TA3N, in order to perform feature alignment for the source domain and the target domain. Our method (without model ensemble) ranks 4th among this year's teams on the test set of EPIC-KITCHENS-100.
翻译:在本报告中,我们介绍了2022年 EPIC-Kitchens 不受监督的Done Aditation (UDA) 挑战(UDA) 的呈件的技术细节。 现有的UDA方法将从整个视频剪辑中提取的全源和目标领域的全球特征统一起来,但在视频识别中却受到功能匹配的空间冗余的影响。 我们的动力是,在多数情况下,每个视频框架中的小图像区域能够为行动识别任务提供足够的信息,因此我们提议利用信息图像区域实现高效域对齐。 具体地说,我们首先使用轻量级CNN来提取输入的双流视频框的全球信息,并通过不同的基于内插选择战略选择信息图像补丁。 然后,视频框和图像补丁的本地信息通过现有的视频适应方法(即TA3N)处理,以便执行源域和目标领域的特征对齐。 我们的方法(没有模型组合)今年在EPIC-KITENS-100测试集的团队中排名第四。