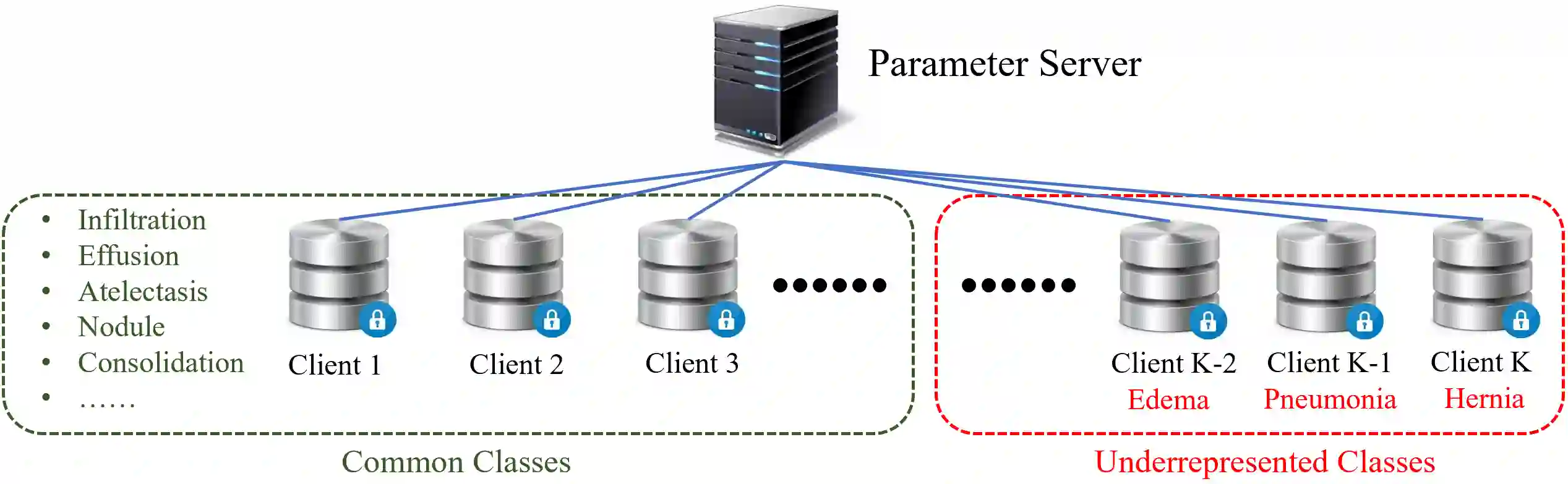
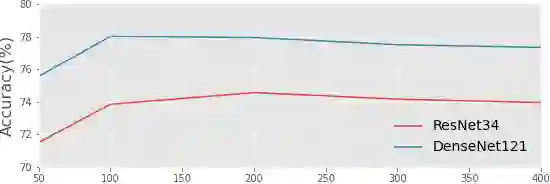
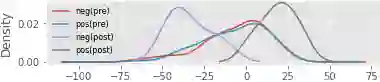
Using decentralized data for federated training is one promising emerging research direction for alleviating data scarcity in the medical domain. However, in contrast to large-scale fully labeled data commonly seen in general object recognition tasks, the local medical datasets are more likely to only have images annotated for a subset of classes of interest due to high annotation costs. In this paper, we consider a practical yet under-explored problem, where underrepresented classes only have few labeled instances available and only exist in a few clients of the federated system. We show that standard federated learning approaches fail to learn robust multi-label classifiers with extreme class imbalance and address it by proposing a novel federated learning framework, FedFew. FedFew consists of three stages, where the first stage leverages federated self-supervised learning to learn class-agnostic representations. In the second stage, the decentralized partially labeled data are exploited to learn an energy-based multi-label classifier for the common classes. Finally, the underrepresented classes are detected based on the energy and a prototype-based nearest-neighbor model is proposed for few-shot matching. We evaluate FedFew on multi-label thoracic disease classification tasks and demonstrate that it outperforms the federated baselines by a large margin.
翻译:使用分散化数据进行联邦培训是缓解医疗领域数据稀缺的一个有希望的新研究方向,然而,与一般物体识别任务中常见的大规模全标签全标签数据相比,当地医疗数据集更有可能仅仅对一组感兴趣的类别有附加说明的图像,因为注释成本高。在本文中,我们认为一个实际但探索不足的问题,即代表性不足的类别只有很少的标签实例,并且只存在于联邦系统的几个客户中。我们表明,标准化的联邦化学习方法未能学习具有极端等级不平衡的强有力多标签分类标签,而未能通过提出新的联邦化学习框架(FedFew)加以解决。FedFew由三个阶段组成,第一阶段利用联邦化的自我监督学习学习学习学习班级的学习。在第二阶段,分散化部分标签数据被用于学习通用分类的基于能源的多标签分类器。最后,基于能源和基于原型近邻模型的近级模型模型模型检测到代表性的分类,并用新的联合化学习框架(FedFedFew) 。我们建议通过少数阶段的基底基比值来测试它。