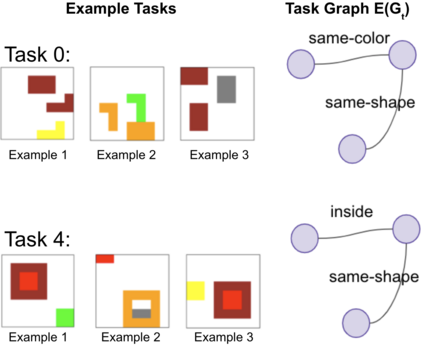
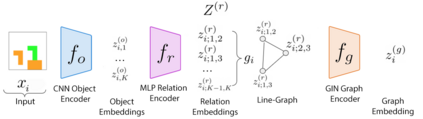
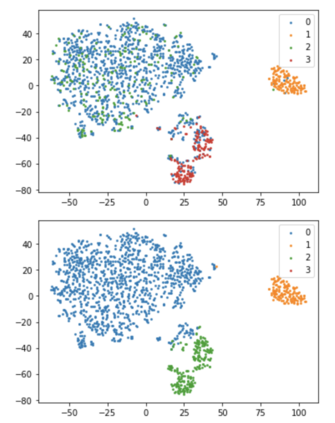
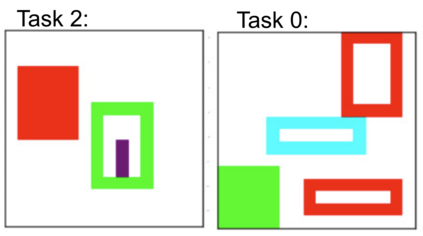
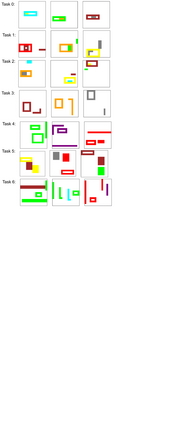
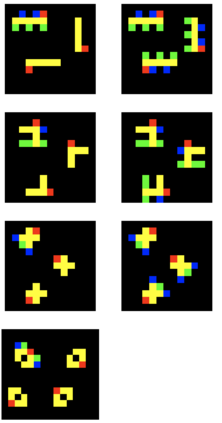
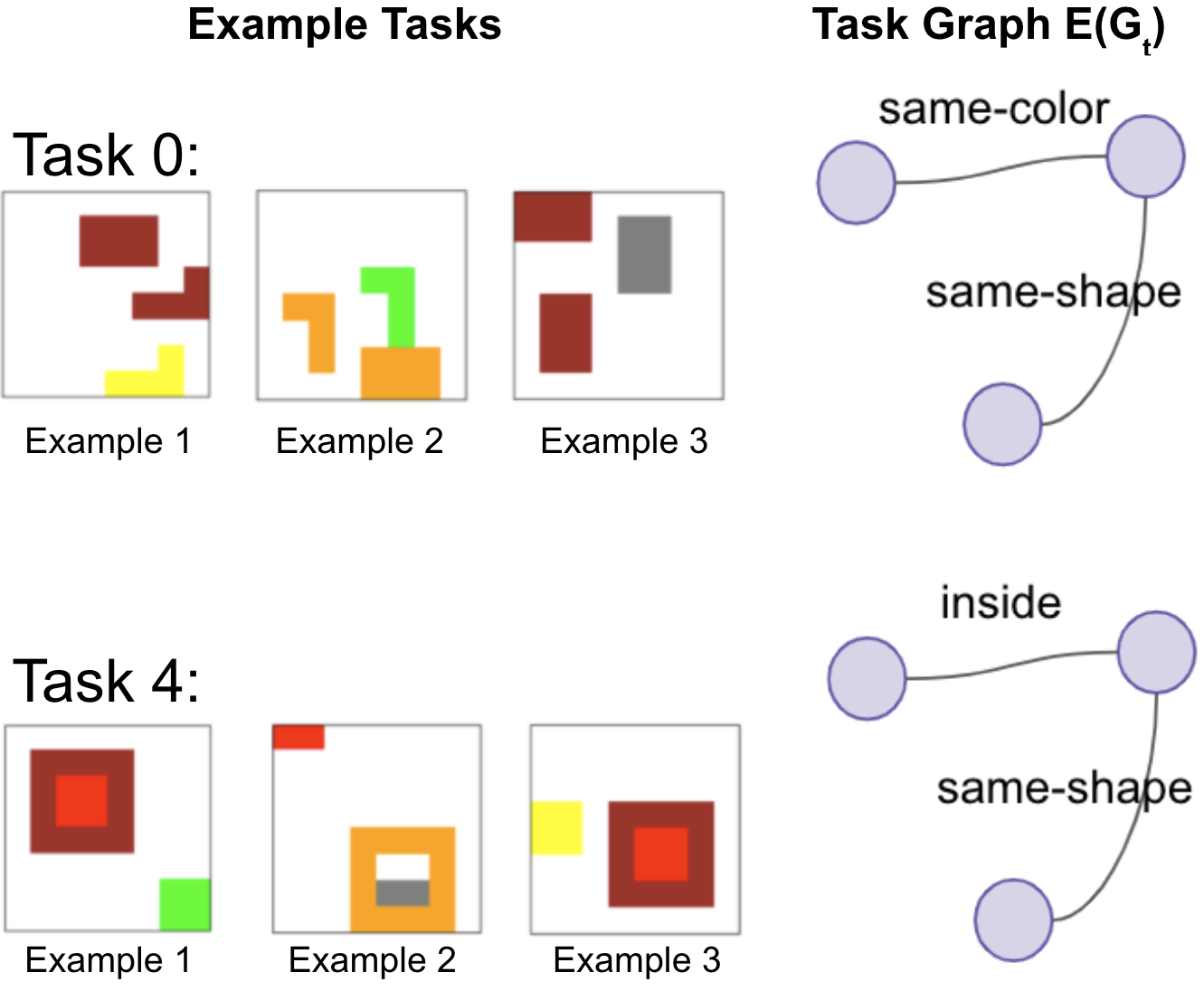
Visual relations form the basis of understanding our compositional world, as relationships between visual objects capture key information in a scene. It is then advantageous to learn relations automatically from the data, as learning with predefined labels cannot capture all possible relations. However, current relation learning methods typically require supervision, and are not designed to generalize to scenes with more complicated relational structures than those seen during training. Here, we introduce ViRel, a method for unsupervised discovery and learning of Visual Relations with graph-level analogy. In a setting where scenes within a task share the same underlying relational subgraph structure, our learning method of contrasting isomorphic and non-isomorphic graphs discovers the relations across tasks in an unsupervised manner. Once the relations are learned, ViRel can then retrieve the shared relational graph structure for each task by parsing the predicted relational structure. Using a dataset based on grid-world and the Abstract Reasoning Corpus, we show that our method achieves above 95% accuracy in relation classification, discovers the relation graph structure for most tasks, and further generalizes to unseen tasks with more complicated relational structures.
翻译:视觉关系构成了理解我们组成世界的基础, 因为视觉物体之间的关系在一幕中捕捉关键信息。 然后从数据中自动学习关系是有利的, 因为使用预定义的标签学习无法捕捉所有可能的关系。 但是, 当前的关系学习方法通常需要监督, 而不是设计为向比培训期间所见更为复杂的关系结构的场景进行概括化。 在这里, 我们引入 ViRel, 这是一种以图形级类比来进行未经监督的发现和学习视觉关系的方法。 在一种环境中, 任务内的场景可以分享相同的基本关系子绘图结构。 我们学习的对比性和非线形图形方法以不受监督的方式发现任务之间的关系。 一旦了解了关系, Virel 就可以通过对预测的关系结构进行分解, 从而检索每一项任务的共同关系图结构。 我们使用基于网格世界和抽象理性公司的数据集, 显示我们的方法在相关分类中达到95%的精确度, 发现大多数任务的关系图表结构, 并进一步概括到与复杂关系结构的无形任务。