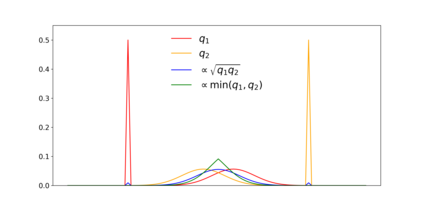
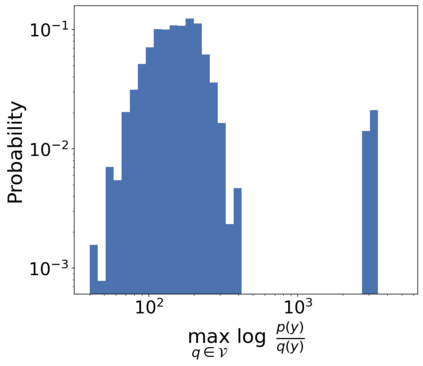
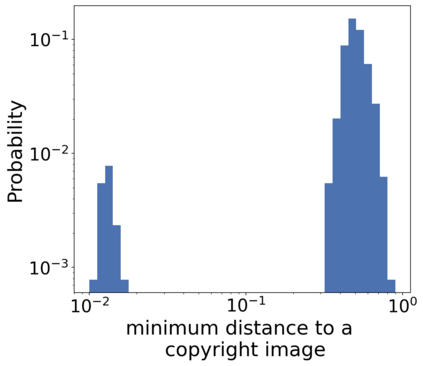
There is a growing concern that learned conditional generative models may output samples that are substantially similar to some copyrighted data $C$ that was in their training set. We give a formal definition of $\textit{near access-freeness (NAF)}$ and prove bounds on the probability that a model satisfying this definition outputs a sample similar to $C$, even if $C$ is included in its training set. Roughly speaking, a generative model $p$ is $\textit{$k$-NAF}$ if for every potentially copyrighted data $C$, the output of $p$ diverges by at most $k$-bits from the output of a model $q$ that $\textit{did not access $C$ at all}$. We also give generative model learning algorithms, which efficiently modify the original generative model learning algorithm in a black box manner, that output generative models with strong bounds on the probability of sampling protected content. Furthermore, we provide promising experiments for both language (transformers) and image (diffusion) generative models, showing minimal degradation in output quality while ensuring strong protections against sampling protected content.
翻译:人们日益担心的是,所学的有条件基因化模型可能会产生与培训中的某些版权数据(C$)基本相似的样本。我们正式定义了美元(textit{near access-freeness (NAF)$),并证明符合这一定义的模型产生类似C$的样本的可能性,即使将C$纳入其培训组。粗略地说,如果对每一种可能版权数据(C$)而言,基因化模型($\textit{k$-NAF})的输出与模型产出($\textit{textness]}没有完全获得$C$(NAF)美元(NAF)的输出相差最多为k美元($-bit)的输出。我们还给出了基因化模型学习算法,这些算法有效地修改了原始基因化模型学习算法,以黑箱方式对抽样内容的概率有很强的约束。此外,我们为语言(翻译)和图像(discrition)的基因化模型提供了很有希望的实验,显示产出质量的退化程度,同时确保严格的取样内容受到保护。