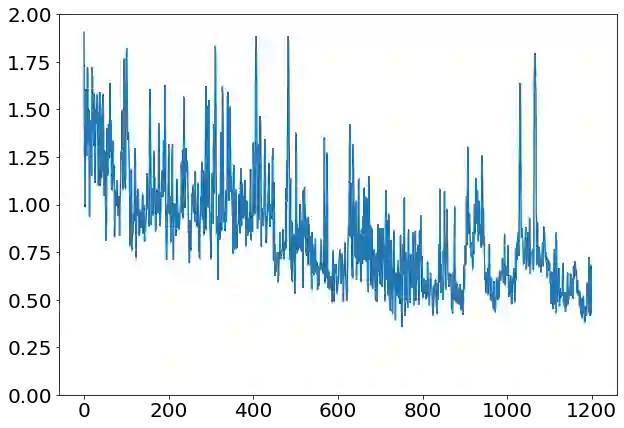
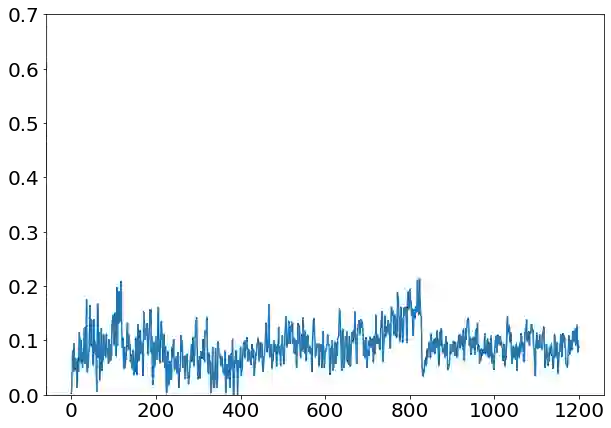
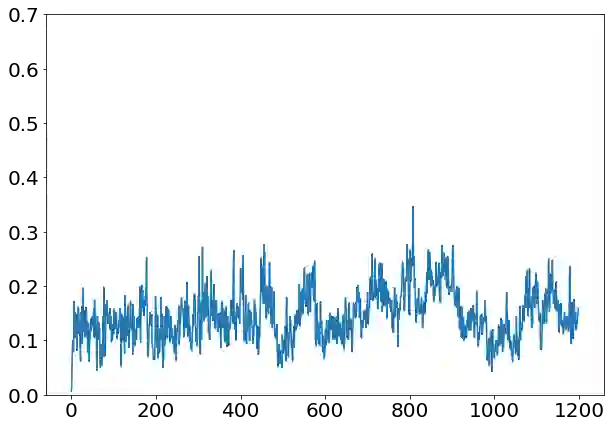
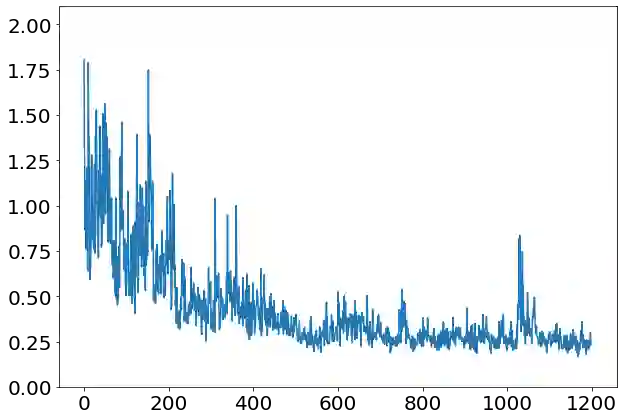
Solving the convergence issues of Generative Adversarial Networks (GANs) is one of the most outstanding problems in generative models. In this work, we propose a novel activation function to be used as output of the generator agent. This activation function is based on the Smirnov probabilistic transformation and it is specifically designed to improve the quality of the generated data. In sharp contrast with previous works, our activation function provides a more general approach that deals not only with the replication of categorical variables but with any type of data distribution (continuous or discrete). Moreover, our activation function is derivable and therefore, it can be seamlessly integrated in the backpropagation computations during the GAN training processes. To validate this approach, we evaluate our proposal against two different data sets: a) an artificially rendered data set containing a mixture of discrete and continuous variables, and b) a real data set of flow-based network traffic data containing both normal connections and cryptomining attacks. To evaluate the fidelity of the generated data, we analyze both their results in terms of quality measures of statistical nature and also regarding the use of these synthetic data to feed a nested machine learning-based classifier. The experimental results evince a clear outperformance of the GAN network tuned with this new activation function with respect to both a na\"ive mean-based generator and a standard GAN. The quality of the data is so high that the generated data can fully substitute real data for training the nested classifier without a fall in the obtained accuracy. This result encourages the use of GANs to produce high-quality synthetic data that are applicable in scenarios in which data privacy must be guaranteed.
翻译:解决 General Adversarial Network (GANs) 的趋同问题是基因化模型中最突出的问题之一。 在这项工作中,我们提出一个新的激活功能,作为发电机代理器的输出。 这个激活功能以Smirnov 概率转换为基础,专门设计来提高生成数据的质量。 与以前的工作形成鲜明对比, 我们的激活功能提供了一个更宽泛的方法, 不仅处理绝对变量的复制, 也处理任何类型的数据分布( 连续或离散) 。 此外, 我们的激活功能是可以衍生出来的, 因此, 在 GAN 培训过程中, 它可以完全融入到后再调整计算中。 为了验证这一方法, 我们用两个不同的数据集来评估我们的建议: a) 人工制作的数据集, 包含离散和连续变量的组合, b) 真实的基于流基网络流量的数据流量数据, 包含正常的连接和加密攻击。 为了评价生成的数据的准确性, 我们从统计性质的计量中分析其结果, 因此, 也可以在 GAN 高级数据升级的精确性 数据升级后, 将这些数据的高级数据转换为在 GAN 的高级数据库中学习。