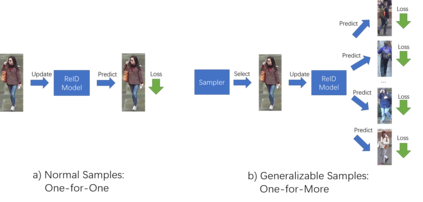
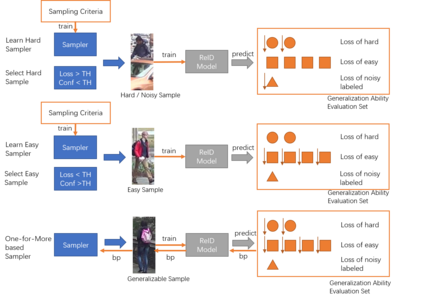
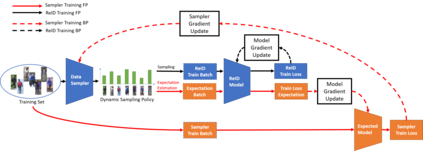
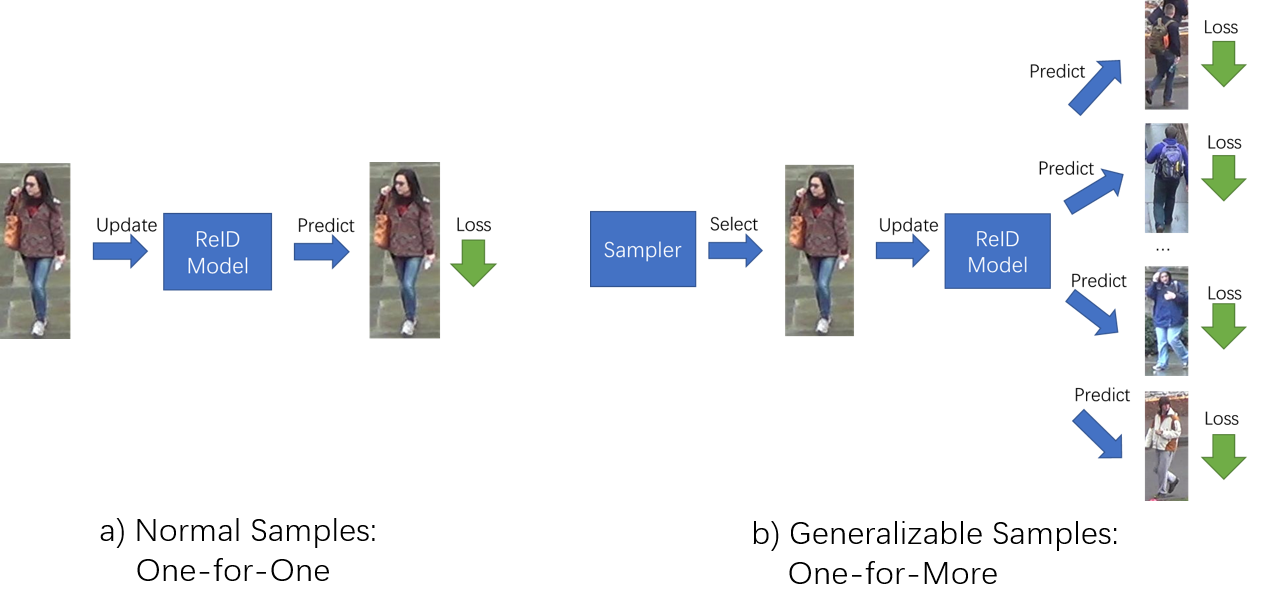
Current training objectives of existing person Re-IDentification (ReID) models only ensure that the loss of the model decreases on selected training batch, with no regards to the performance on samples outside the batch. It will inevitably cause the model to over-fit the data in the dominant position (e.g., head data in imbalanced class, easy samples or noisy samples). %We call the sample that updates the model towards generalizing on more data a generalizable sample. The latest resampling methods address the issue by designing specific criterion to select specific samples that trains the model generalize more on certain type of data (e.g., hard samples, tail data), which is not adaptive to the inconsistent real world ReID data distributions. Therefore, instead of simply presuming on what samples are generalizable, this paper proposes a one-for-more training objective that directly takes the generalization ability of selected samples as a loss function and learn a sampler to automatically select generalizable samples. More importantly, our proposed one-for-more based sampler can be seamlessly integrated into the ReID training framework which is able to simultaneously train ReID models and the sampler in an end-to-end fashion. The experimental results show that our method can effectively improve the ReID model training and boost the performance of ReID models.
翻译:现有人员再识别(ReID)模型的当前培训目标只能确保模型损失在选定的培训批次上减少,而没有考虑到批外样品的性能,使模型损失在选定的培训批次上减少,这不可避免地导致模型在主导位置上(例如,不平衡的类别、容易的样品或吵闹的样品中,头部数据)数据过大。%我们将更新模型以普及更多数据的模型的样本称为通用样本。最新的再抽样方法解决这一问题,方法是设计具体标准,选择具体样本,对模型进行更概括化的特定样本,对某些类型的数据(例如,硬样品、尾巴数据)进行培训,而这种样本不适应不一致的真实世界再识别数据分布。因此,本文提出的一个一等量的培训目标,不是简单地假设哪些样本可以概括一般的类别,而是直接将选定样品的通用能力作为损失函数,学习一个抽样人自动选择可概括的样品。更重要的是,我们提议的一等量的取样员可以顺利地纳入ReID培训框架,这种框架能够同时培训ReID模型,而是有效地改进样品的模型。