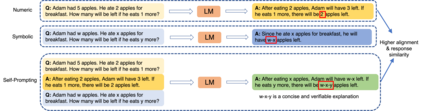
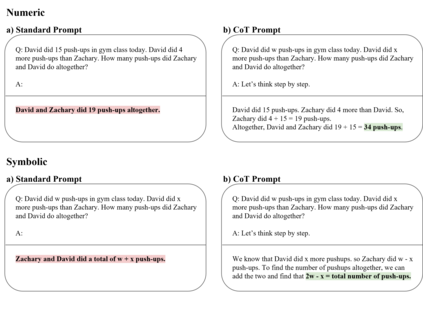
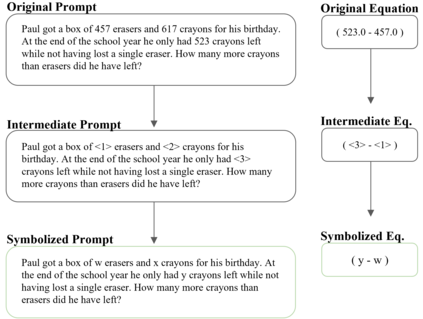
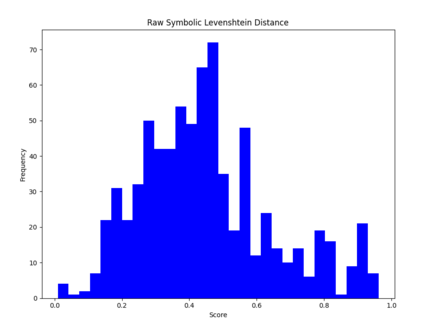
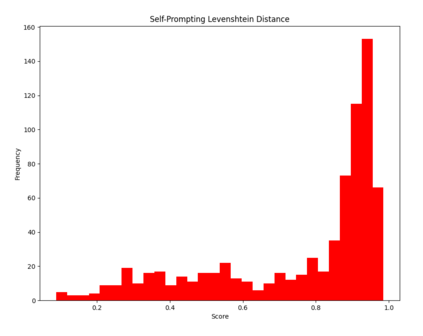
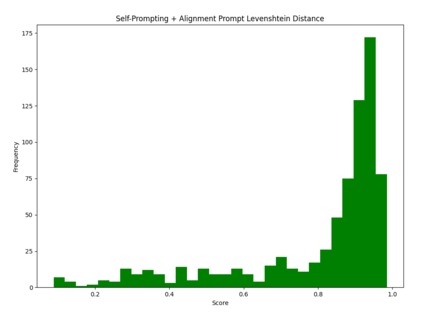
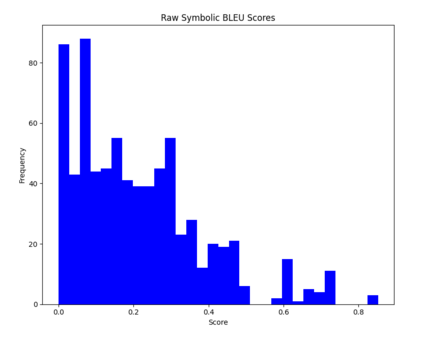
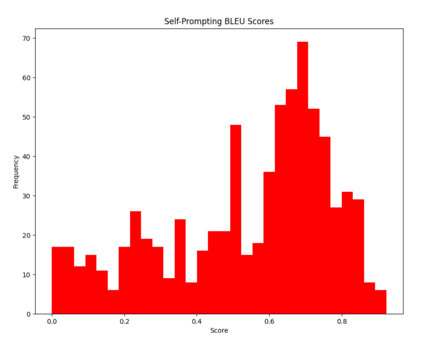
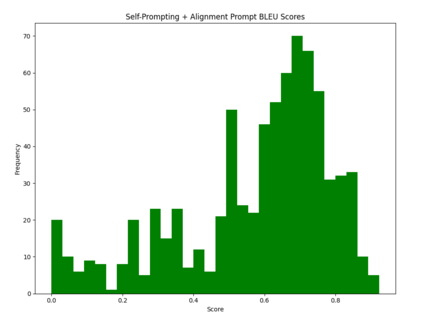
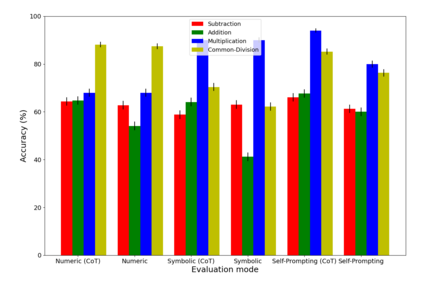
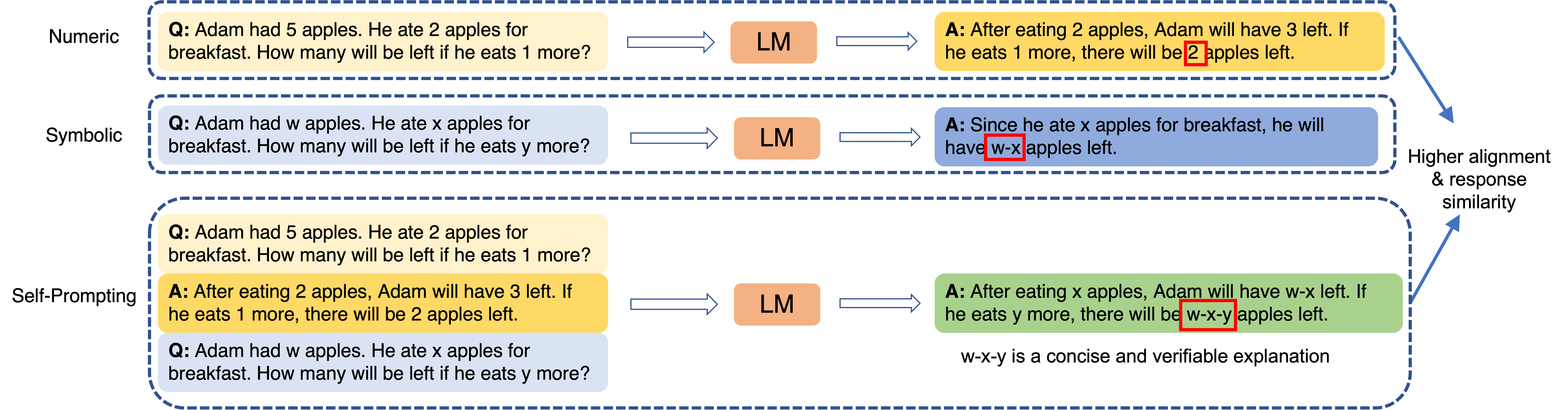
Large language models (LLMs) have revolutionized NLP by solving downstream tasks with little to no labeled data. Despite their versatile abilities, the larger question of their ability to reason remains ill-understood. This paper addresses reasoning in math word problems (MWPs) by studying symbolic versions of the numeric problems, since a symbolic expression is a "concise explanation" of the numeric answer. We create and use a symbolic version of the SVAMP dataset and find that GPT-3's davinci-002 model also has good zero-shot accuracy on symbolic MWPs. To evaluate the faithfulness of the model's reasoning, we go beyond accuracy and additionally evaluate the alignment between the final answer and the outputted reasoning, which correspond to numeric and symbolic answers respectively for MWPs. We explore a self-prompting approach to encourage the symbolic reasoning to align with the numeric answer, thus equipping the LLM with the ability to provide a concise and verifiable reasoning and making it more interpretable. Surprisingly, self-prompting also improves the symbolic accuracy to be higher than both the numeric and symbolic accuracies, thus providing an ensembling effect. The SVAMP_Sym dataset will be released for future research on symbolic math problems.
翻译:暂无翻译