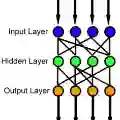
The training of neural networks requires tedious and often manual tuning of the network architecture. We propose a systematic method to insert new layers during the training process, which eliminates the need to choose a fixed network size before training. Our technique borrows techniques from constrained optimization and is based on first-order sensitivity information of the objective with respect to the virtual parameters that additional layers, if inserted, would offer. We consider fully connected feedforward networks with selected activation functions as well as residual neural networks. In numerical experiments, the proposed sensitivity-based layer insertion technique exhibits improved training decay, compared to not inserting the layer. Furthermore, the computational effort is reduced in comparison to inserting the layer from the beginning. The code is available at \url{https://github.com/LeonieKreis/layer_insertion_sensitivity_based}.
翻译:暂无翻译