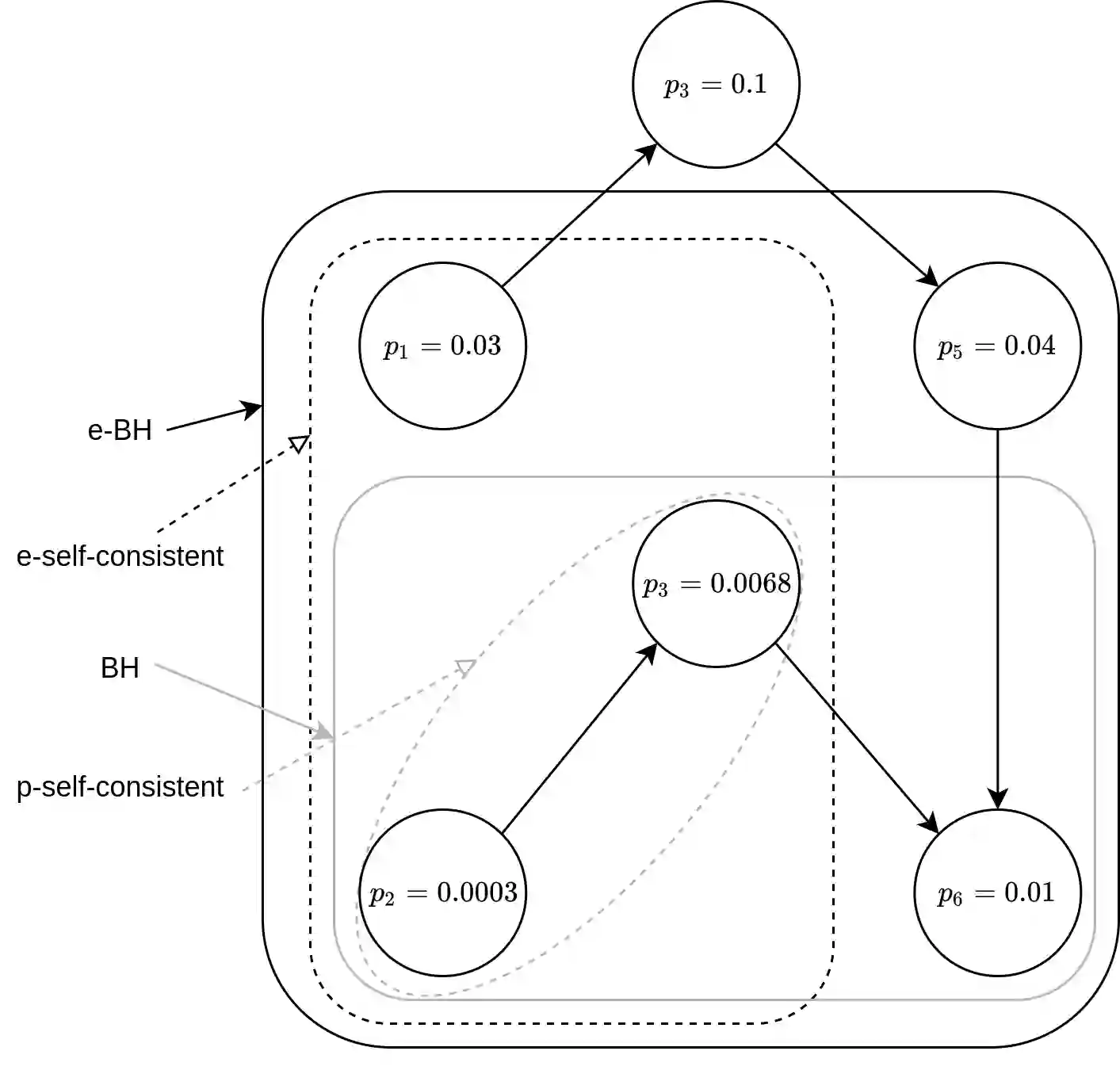
In bandit multiple hypothesis testing, each arm corresponds to a different null hypothesis that we wish to test, and the goal is to design adaptive algorithms that correctly identify large set of interesting arms (true discoveries), while only mistakenly identifying a few uninteresting ones (false discoveries). One common metric in non-bandit multiple testing is the false discovery rate (FDR). We propose a unified, modular framework for bandit FDR control that emphasizes the decoupling of exploration and summarization of evidence. We utilize the powerful martingale-based concept of "e-processes" to ensure FDR control for arbitrary composite nulls, exploration rules and stopping times in generic problem settings. In particular, valid FDR control holds even if the reward distributions of the arms could be dependent, multiple arms may be queried simultaneously, and multiple (cooperating or competing) agents may be querying arms, covering combinatorial semi-bandit type settings as well. Prior work has considered in great detail the setting where each arm's reward distribution is independent and sub-Gaussian, and a single arm is queried at each step. Our framework recovers matching sample complexity guarantees in this special case, and performs comparably or better in practice. For other settings, sample complexities will depend on the finer details of the problem (composite nulls being tested, exploration algorithm, data dependence structure, stopping rule) and we do not explore these; our contribution is to show that the FDR guarantee is clean and entirely agnostic to these details.
翻译:在土匪多重假设测试中,每个手臂都对应着一个不同的无效假设,我们希望测试,目标是设计适应性算法,正确识别一大批有趣的武器(真正的发现),同时只错误地识别一些不感兴趣的武器(虚假发现)。非土匪多重测试的一个共同标准是虚假的发现率(FDR )。我们为土匪FDR控制提出了一个统一的模块化框架,强调勘探和证据汇总的脱钩。我们利用强大的基于马丁格的“电子过程”概念,以确保FDR对任意的复合废铁、勘探规则和在通用问题设置中停止时间的控制。特别是,有效的FDR控制即使武器报酬分配可能依赖,也可以同时询问多个武器,而多个(合作或竞争)代理商可能是查询武器,包括组合半土匪类型设置。我们以前的工作非常详细地考虑了每个手臂的奖励分配是独立的和亚撒西兰西语的设置,每个步骤都要对单臂进行控制。我们的框架恢复了这些试样复杂程度,这些样本的精确性保证在特殊的勘探结构中可以追溯到我们的具体数据。