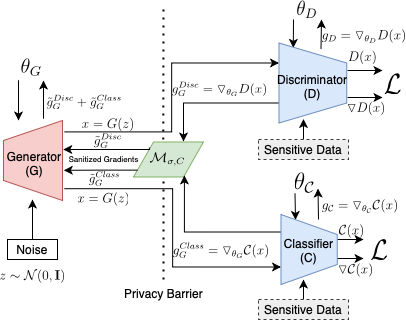
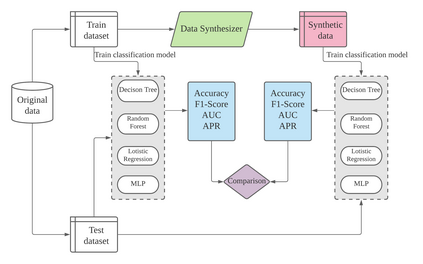
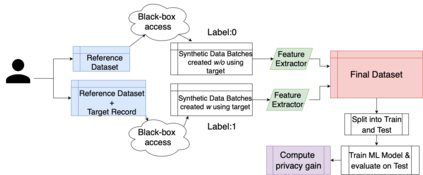
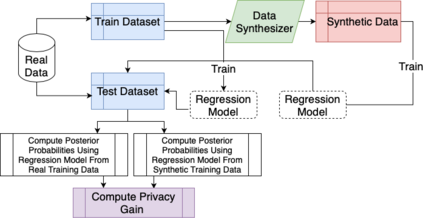
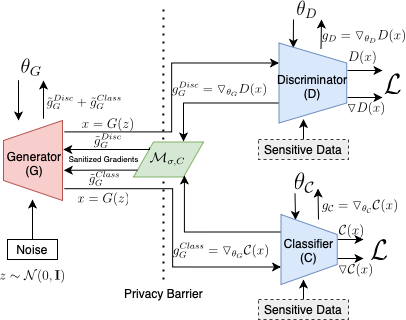
Tabular generative adversarial networks (TGAN) have recently emerged to cater to the need of synthesizing tabular data -- the most widely used data format. While synthetic tabular data offers the advantage of complying with privacy regulations, there still exists a risk of privacy leakage via inference attacks due to interpolating the properties of real data during training. Differential private (DP) training algorithms provide theoretical guarantees for training machine learning models by injecting statistical noise to prevent privacy leaks. However, the challenges of applying DP on TGAN are to determine the most optimal framework (i.e., PATE/DP-SGD) and neural network (i.e., Generator/Discriminator)to inject noise such that the data utility is well maintained under a given privacy guarantee. In this paper, we propose DTGAN, a novel conditional Wasserstein tabular GAN that comes in two variants DTGAN_G and DTGAN_D, for providing a detailed comparison of tabular GANs trained using DP-SGD for the generator vs discriminator, respectively. We elicit the privacy analysis associated with training the generator with complex loss functions (i.e., classification and information losses) needed for high quality tabular data synthesis. Additionally, we rigorously evaluate the theoretical privacy guarantees offered by DP empirically against membership and attribute inference attacks. Our results on 3 datasets show that the DP-SGD framework is superior to PATE and that a DP discriminator is more optimal for training convergence. Thus, we find (i) DTGAN_D is capable of maintaining the highest data utility across 4 ML models by up to 18% in terms of the average precision score for a strict privacy budget, epsilon = 1, as compared to the prior studies and (ii) DP effectively prevents privacy loss against inference attacks by restricting the success probability of membership attacks to be close to 50%.
翻译:最近,出现了一个具有超常特征的隐私关系网(TGAN),以满足综合表层数据的需求。尽管合成表层数据具有遵守隐私条例的优势,但由于培训期间对真实数据的性质进行内插,因此仍然存在着因推断攻击而导致隐私泄漏的风险。不同的私人(DP)培训算法为培训机器学习模式提供了理论保障,办法是注入统计噪音,防止隐私泄漏。然而,在TGAN上应用DP的挑战是确定最理想的框架(即PATE/DP-SGD)和神经网络(即发电机/Dismiminator),以确定遵守隐私条例的优点,但是由于在培训期间对真实数据的特性进行推断,数据效用仍然存在通过推断性GAAN的精确性攻击。在本文中,一个新的条件性Wasserstein Table GAN(DPGAN) 和DGAN_D(DD) 提供了两个变式,用来详细比较用 DP-SGD(即更精确的变异性数据模型,我们用SD) 的精确性数据分析结果比前的精确性数据分析比重数据。