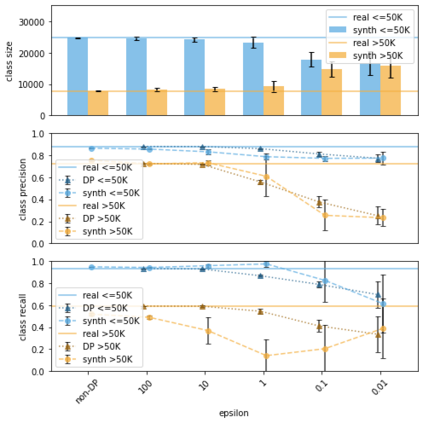
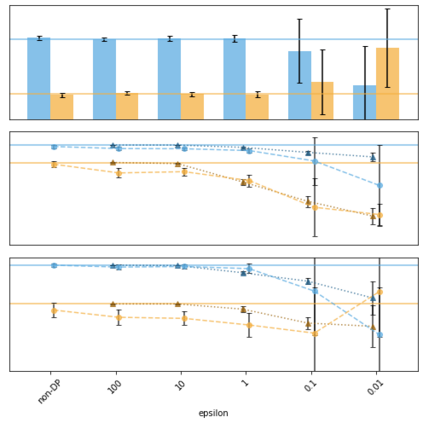
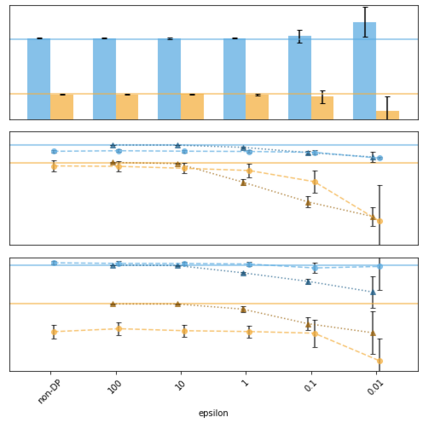
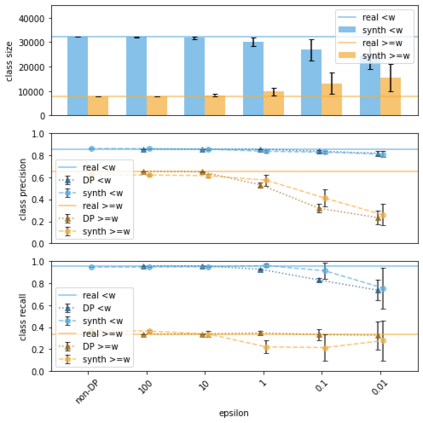
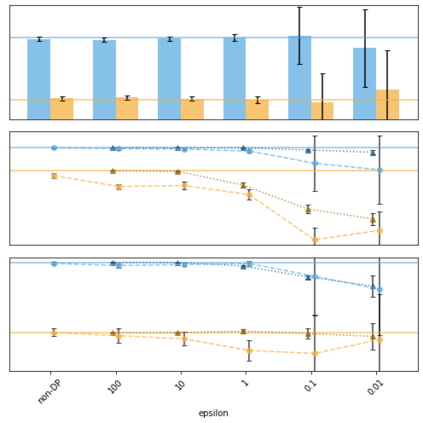
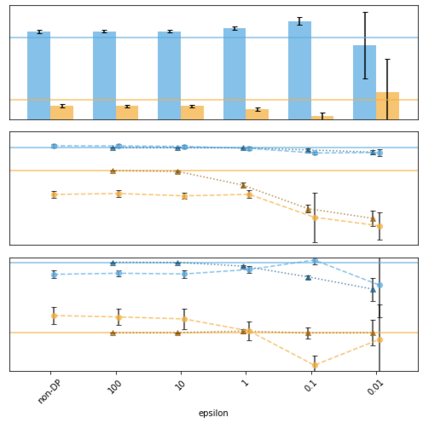
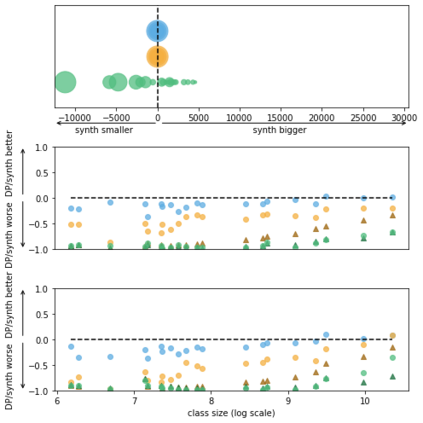
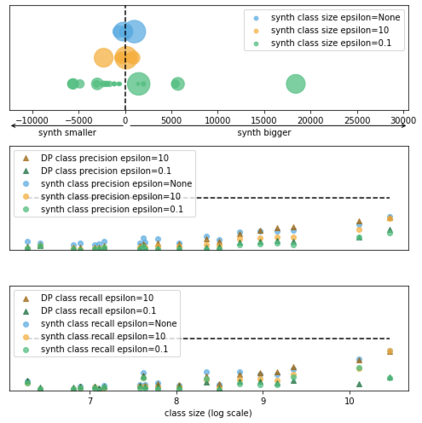
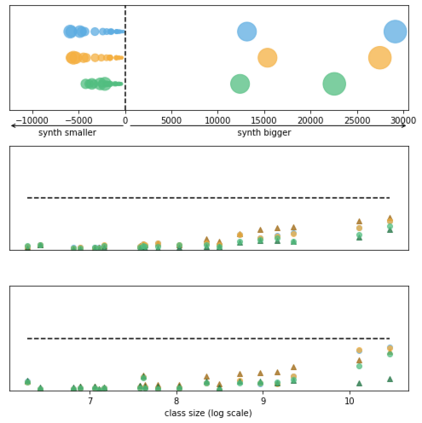
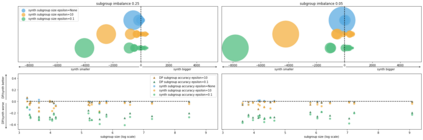
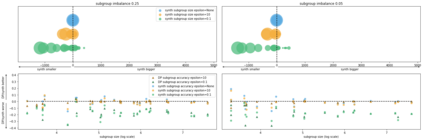
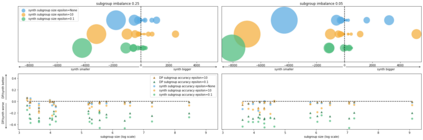
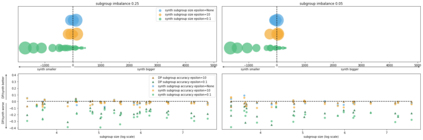
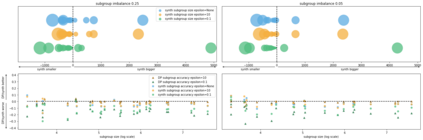
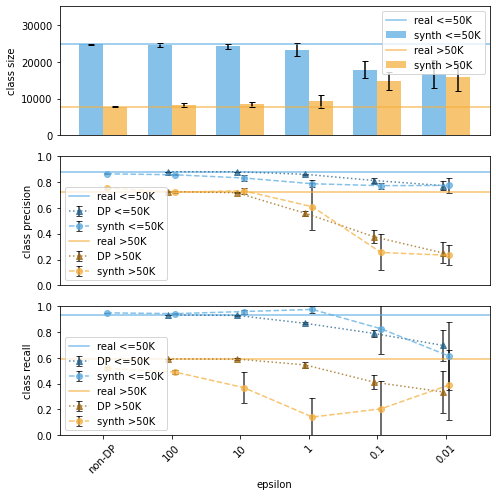
Generative models trained using Differential Privacy (DP) are increasingly used to produce and share synthetic data in a privacy-friendly manner. In this paper, we set out to analyze the impact of DP on these models vis-a-vis underrepresented classes and subgroups of data. We do so from two angles: 1) the size of classes and subgroups in the synthetic data, and 2) classification accuracy on them. We also evaluate the effect of various levels of imbalance and privacy budgets. Our experiments, conducted using three state-of-the-art DP models (PrivBayes, DP-WGAN, and PATE-GAN), show that DP results in opposite size distributions in the generated synthetic data. More precisely, it affects the gap between the majority and minority classes and subgroups, either reducing it (a "Robin Hood" effect) or increasing it ("Matthew" effect). However, both of these size shifts lead to similar disparate impacts on a classifier's accuracy, affecting disproportionately more the underrepresented subparts of the data. As a result, we call for caution when analyzing or training a model on synthetic data, or risk treating different subpopulations unevenly, which might also lead to unreliable conclusions.
翻译:使用不同隐私(DP)培训的生成模型越来越多地用于以方便隐私的方式制作和分享合成数据。在本文中,我们准备分析DP对这些模型相对于代表性不足的数据类别和分组的影响。我们从两个角度分析DP对这些模型的影响:1) 合成数据中的类别和分组规模,2) 分类准确性。我们还评估了不同程度的不平衡和隐私预算的影响。我们使用三种最先进的DP模型(PrivBayes、DP-WGAN和PATE-GAN)进行的实验表明,DP的结果在生成的合成数据中出现不同大小的分布。更准确地说,它影响到多数类和少数类和分组之间的差距,要么缩小(Robin Hood效应),要么增加(“Mathew”效应)。然而,这两种规模的变化都会导致对分类者准确性产生类似的不同影响,对数据代表性过大的子部分影响。结果,我们呼吁在分析或培训合成数据模型时谨慎对待不同次层的风险,因为后者可能会导致不可靠的。