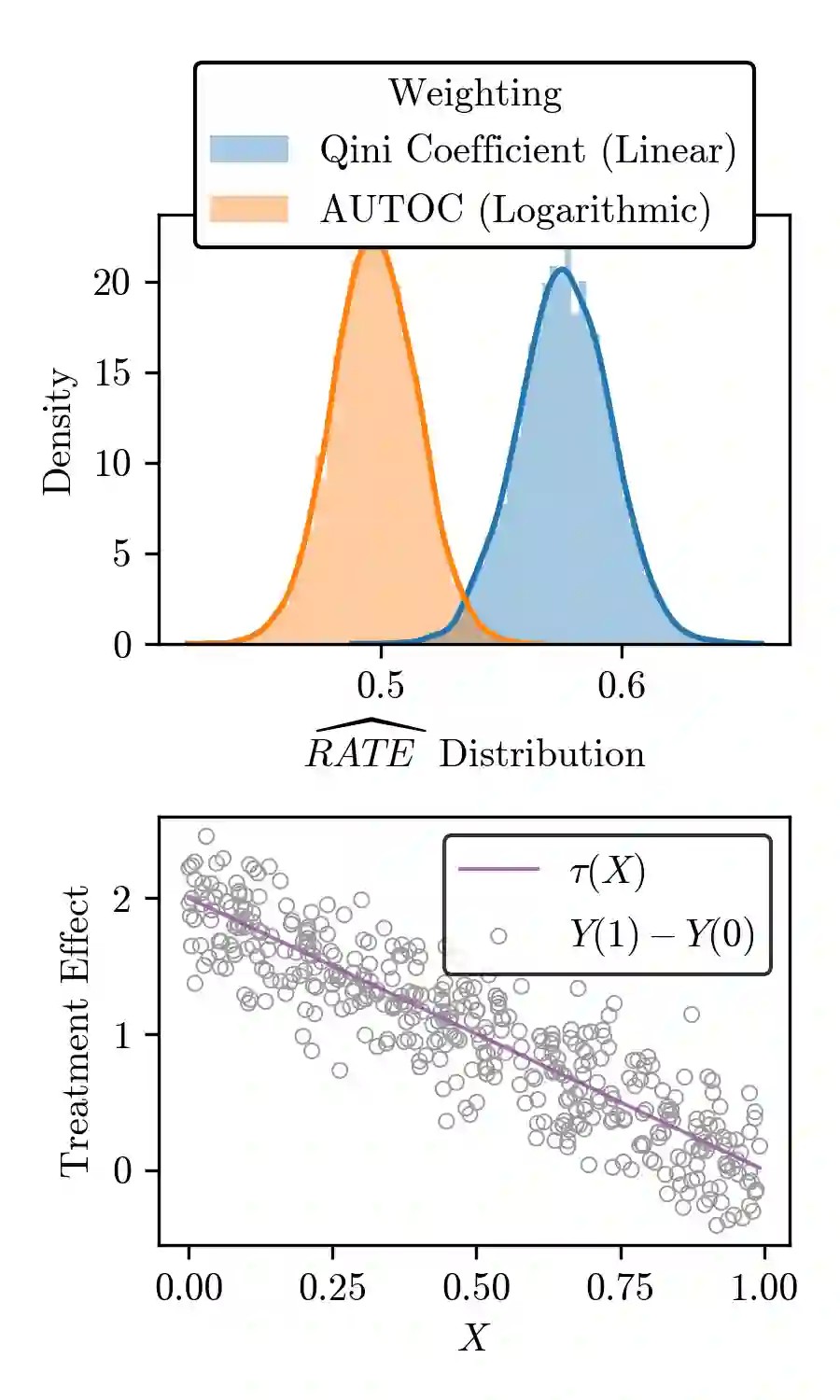
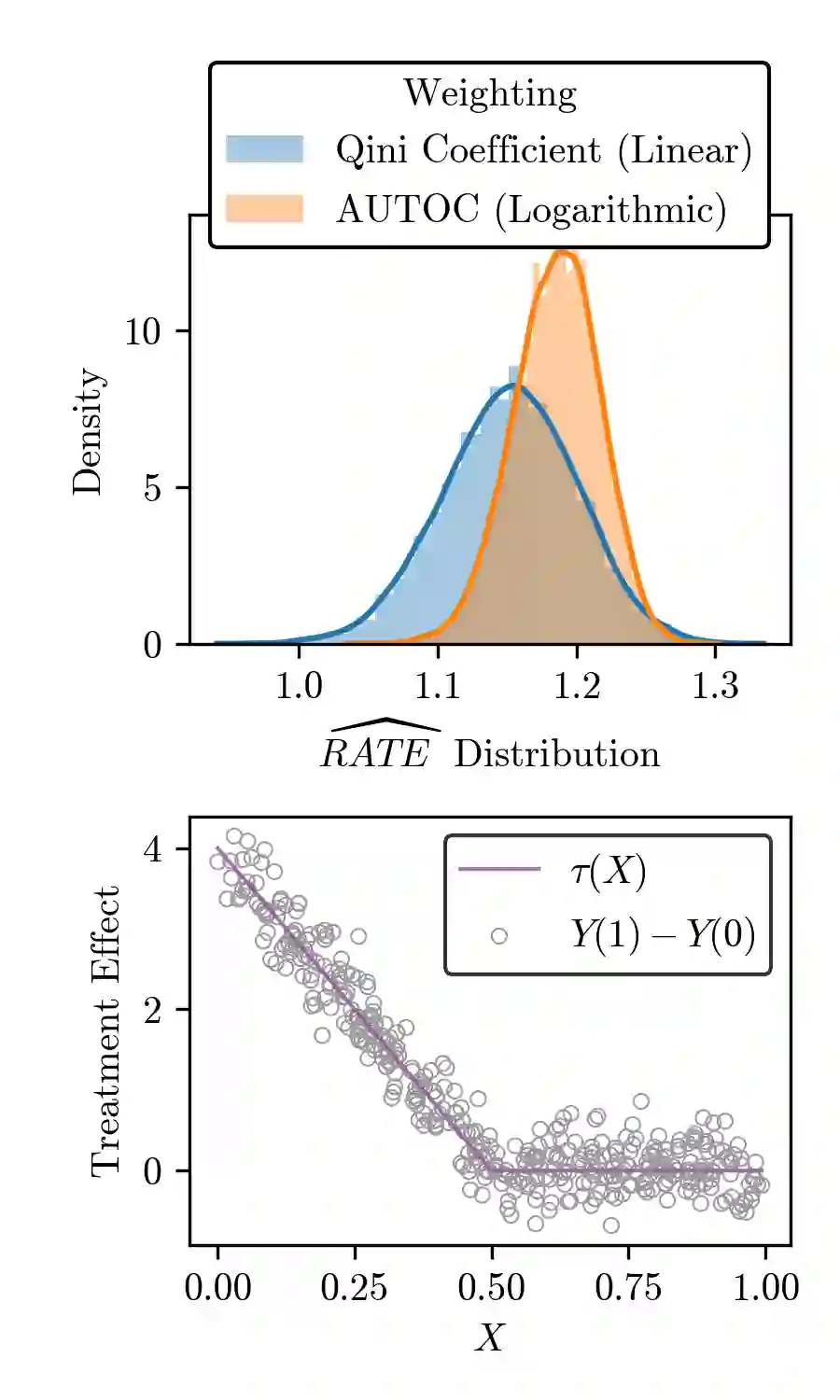
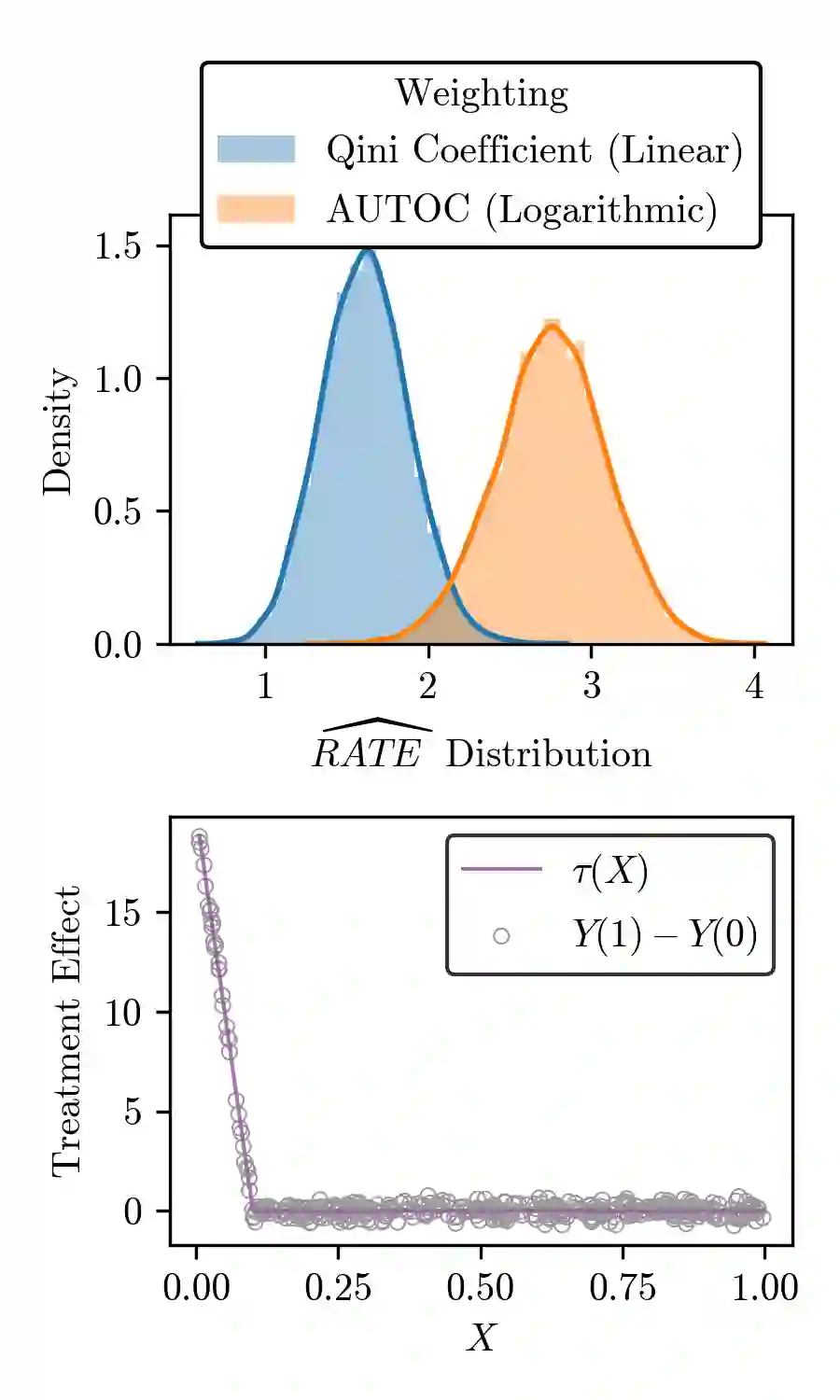
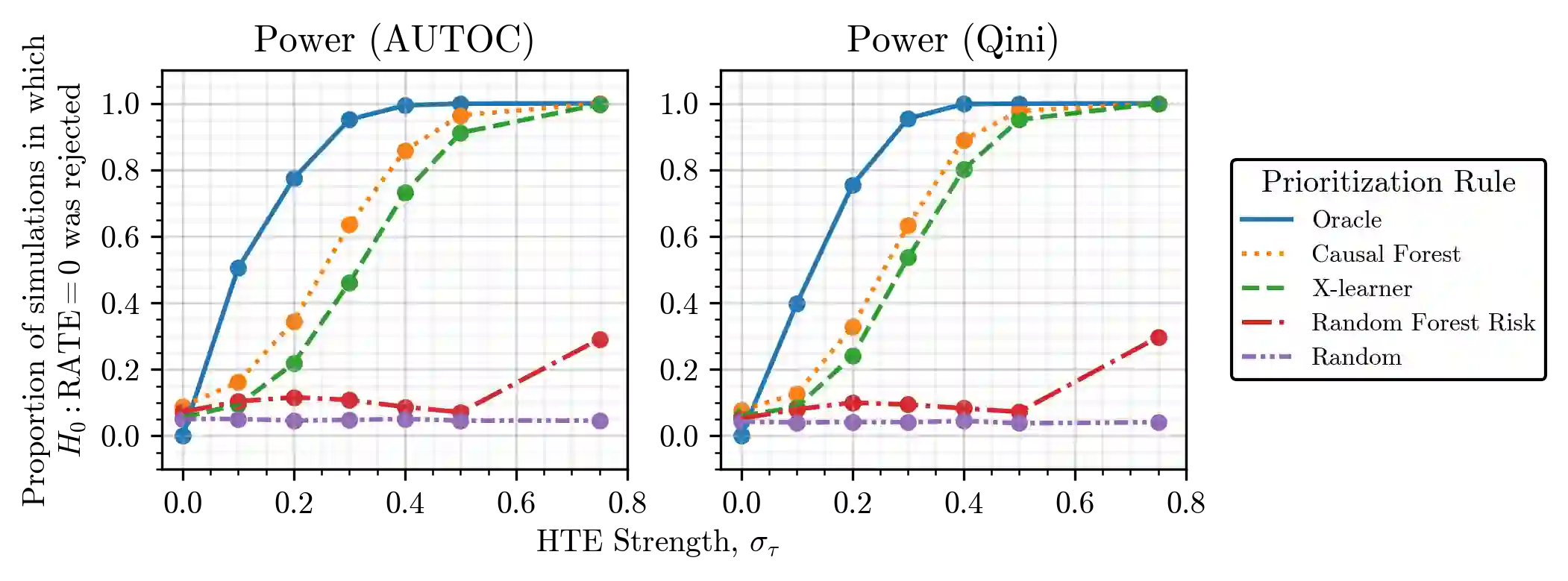
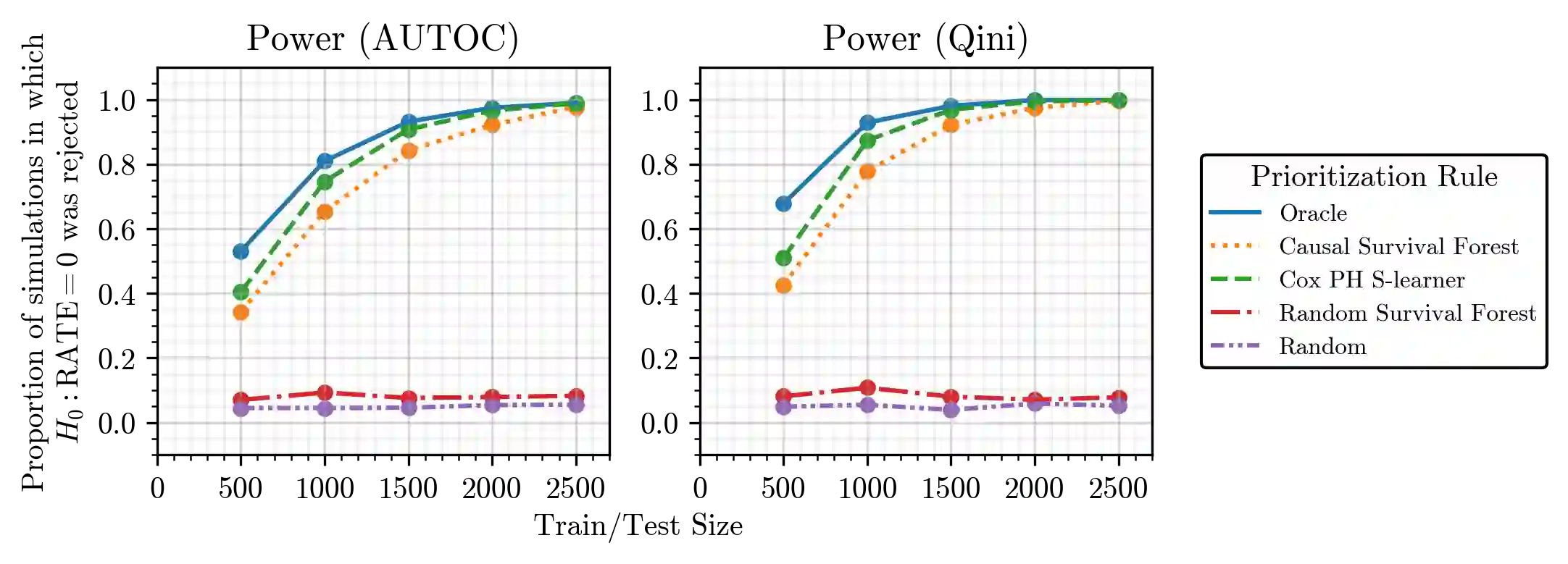
There are a number of available methods that can be used for choosing whom to prioritize treatment, including ones based on treatment effect estimation, risk scoring, and hand-crafted rules. We propose rank-weighted average treatment effect (RATE) metrics as a simple and general family of metrics for comparing treatment prioritization rules on a level playing field. RATEs are agnostic as to how the prioritization rules were derived, and only assesses them based on how well they succeed in identifying units that benefit the most from treatment. We define a family of RATE estimators and prove a central limit theorem that enables asymptotically exact inference in a wide variety of randomized and observational study settings. We provide justification for the use of bootstrapped confidence intervals and a framework for testing hypotheses about heterogeneity in treatment effectiveness correlated with the prioritization rule. Our definition of the RATE nests a number of existing metrics, including the Qini coefficient, and our analysis directly yields inference methods for these metrics. We demonstrate our approach in examples drawn from both personalized medicine and marketing. In the medical setting, using data from the SPRINT and ACCORD-BP randomized control trials, we find no significant evidence of heterogeneous treatment effects. On the other hand, in a large marketing trial, we find robust evidence of heterogeneity in the treatment effects of some digital advertising campaigns and demonstrate how RATEs can be used to compare targeting rules that prioritize estimated risk vs. those that prioritize estimated treatment benefit.
翻译:现有一些方法可用于选择哪些人优先治疗,包括基于治疗效果估计、风险评分和手工制作规则的方法。我们提出按级加权平均治疗效果(REATE)衡量标准,作为在公平竞争环境中比较治疗优先规则的简单和一般的衡量标准。REATE对如何得出优先排序规则是不可知的,只能根据它们如何成功地确定最能从治疗中受益的单位来评估这些方法。我们定义了REATE测算员的大家庭,并证明了一个中心限值,能够在各种随机和观察性研究环境中进行无症状精确的推断。我们提出了使用按级加权平均平均平均平均治疗效果(RETE)衡量标准的理由,并提出了一个框架,用以测试治疗效率差异性规则的假设与优先规则相关。我们对RATE的定义将现有的一些衡量标准,包括Qini系数,以及我们的分析直接得出这些衡量标准的推断方法。我们从个人化医学和营销中提取的一些例子中展示了我们的方法。在医学定位和市场营销过程中,我们用大量的数据来证明,我们从SARBA测试中所使用的大量数据。