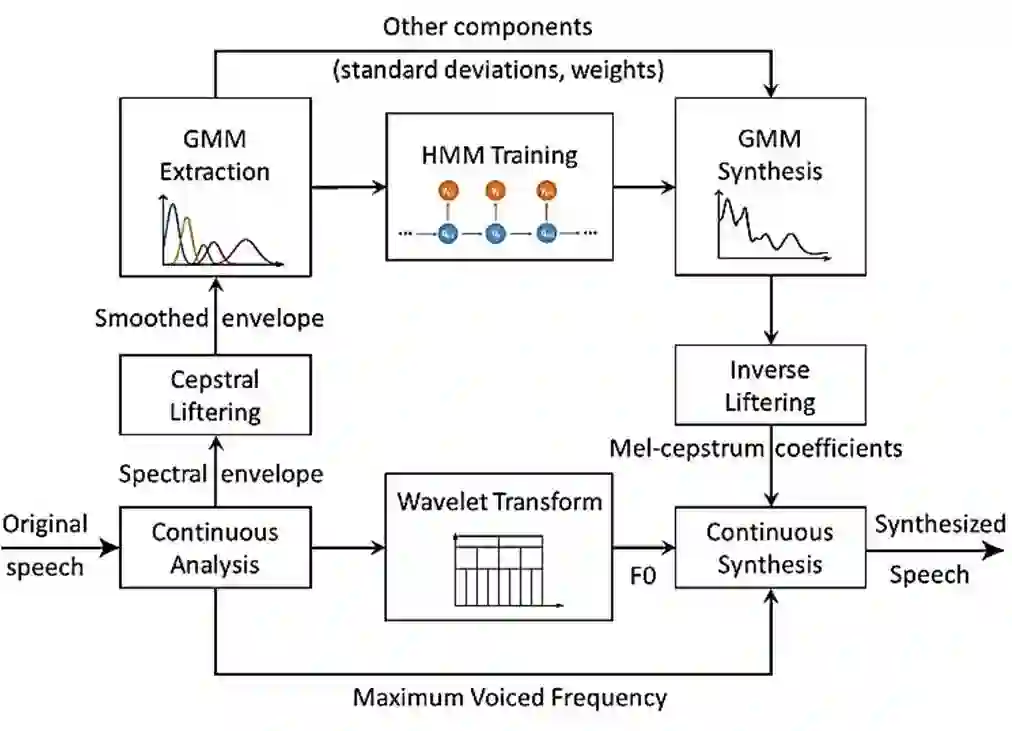
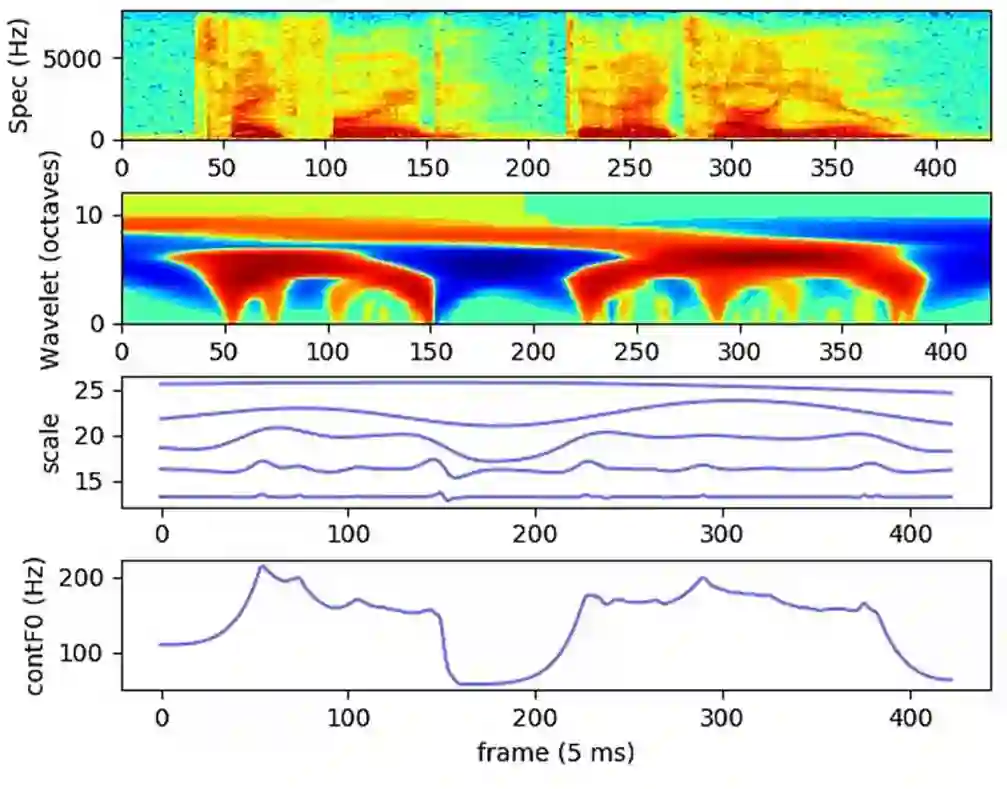
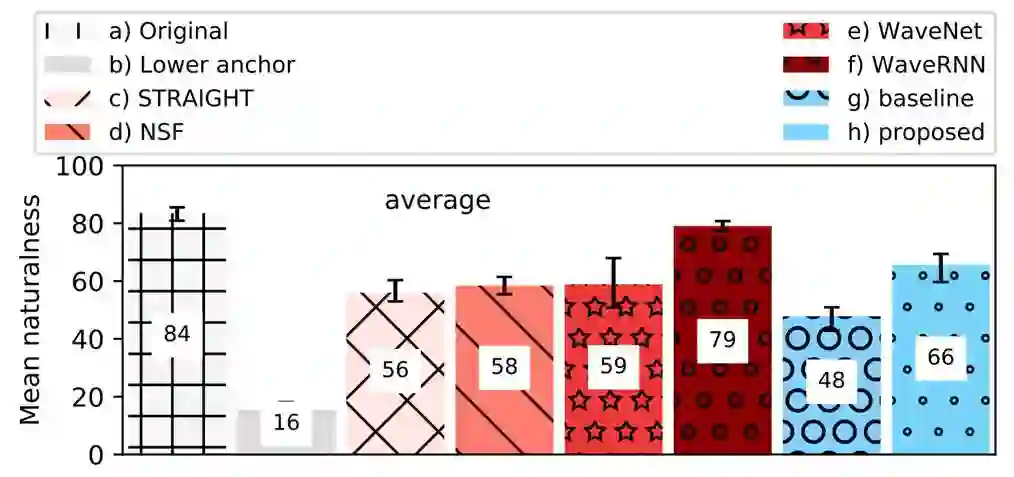
Neural network-based Text-to-Speech has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron2, FastSpeech, FastPitch) usually generate Mel-spectrogram from text and then synthesize speech using vocoder (e.g., WaveNet, WaveGlow, HiFiGAN). Compared with traditional parametric approaches (e.g., STRAIGHT and WORLD), neural vocoder based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust and lack of controllability. In this work, we propose a novel updated vocoder, which is a simple signal model to train and easy to generate waveforms. We use the Gaussian-Markov model toward robust learning of spectral envelope and wavelet-based statistical signal processing to characterize and decompose F0 features. It can retain the fine spectral envelope and achieve high controllability of natural speech. The experimental results demonstrate that our proposed vocoder achieves better naturalness of reconstructed speech than the conventional STRAIGHT vocoder, slightly better than WaveNet, and somewhat worse than the WaveRNN.
翻译:以神经网络为基础的文本到语音已大大提高了合成语音的质量。光学方法(例如,Tacotron2, FastSpeech, FastPitch)通常会从文本中产生Mel-spectrogram,然后使用vocoder(例如,WaveNet,WaveGlow,HiFiGAN)合成语音(例如,WaveNet,WaveGlow,HiFiGAN)与传统的参数学方法(例如,Straight和WorldWorld)相比,基于神经电动的终端到终端模型受到缓慢的推断速度的影响,而合成的语音通常不稳而且缺乏可控性。在这项工作中,我们提出了一个新颖的Vocoder更新的vocoder,这是一个简单的信号模型,用于培训和容易生成波形。我们使用Gausian-Markov模型对光谱信封和波状统计信号处理进行有力的学习,以辨别和解析F0特性。它可以保留精细的光谱包,并实现高控性自然讲话。实验结果表明,我们提议的vocoder 将比常规的波波更差的台更佳的台更佳的台更佳的语音。